Jekyll2024-10-22T08:17:06+00:00https://eotles.com/feed.xmlErkin ÖtleşErkin Ötleş' blog, portfolio, and website. Focused on engineering medicine. Thoughts on artificial intelligence, operations research, healthcare and medicine.Erkin ÖtleşAI Infrastructure: Technical Integration Testing2024-10-22T00:00:00+00:002024-05-08T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-Technical-Integration-TestingNB: this series is still a work in progress.
This post builds off of our previous discussions on healthcare AI infrastructure.
If you are unfamiliar with that infrastructure, it may be helpful to review the posts that cover the AI lifecycle or the general infrastructure landscape.
Overview
Technical Integration Testing
Although I’ve alluded to it, we haven’t formally discussed testing side of integration yet.
Testing all the components needed to technically implement the system is something that I refer to as technical integration testing.
After careful consideration of clinical workflow it is one of the most important steps in the implementation process, imo.
The basic premise of technical integration testing is to double check that you get the expected results from implementation components and that the system functions correct.
This can be tricky because you need a good end-to-end understanding of the system and should approach each of the components from several different perspectives (software engineer, data engineer, ML engineer).
Additionally, we don’t have a standard toolbox to use when we are conducting technical integration testing.
Although I didn’t have a guide book, I tried to approach this process in a systematic manner through the course of the M-CURES project.
I ended up creating several techniques that can be … [TODO: transition]
A couple of the techniques were simply around getting more information from the integration system.
These involved closely examining the way data was being passed to and from the model.
This is crucial because small changes in data format coming in can have big downstream consequences.
As such we developed some techniques that allowed us to debug how our model was receiving and processing data.
These techniques utilized the Python error console that Epic provided in the ECCP management dashboard.
We built custom errors that helped assure that we were receiving and processing data in the correct manner.
This process helped us refine our mental model of ECCP to align with the way it actually works.
Part of the ECCP production debugging was inspired by another line of testing that we had conducted, which was diffing predictions.
Diffing predictions grew out of a technique we had developed for analyzing prospective performance degradation.
The basic premise is straightforward.
Run the same information through two different implementations of the same
These techniques were:
ECCP Production Debugging
Diffing PatientLevel Predictions
ECCP Production Debugging
During this implementation process I developed 2 techniques that could ev
some approaches for That being said, I did take a shot at doing a systematic
This is an area I’m particularly interested in and hopefully I can convince some peer reviewers that
It would be
Its tricky as you have to you need to approach the system from a c
During this process
- slate vs. manually running the model
- production debugging
]]>Erkin ÖtleşAI Infrastructure Example: *C. difficile* Infection Risk2024-10-21T00:00:00+00:002024-04-12T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-CDINB: this series is still a work in progress.
This post builds off of our previous discussions on healthcare AI infrastructure.
It may be helpful to review the posts that cover the general lay of healthcare IT land, development infrastructure, and implementation infrastructure.
C. difficile Infection Model
We will be discussing the technical integration of a model that we have running at the University of Michigan.
We developed this model with the intent to C. difficile infection risk stratification
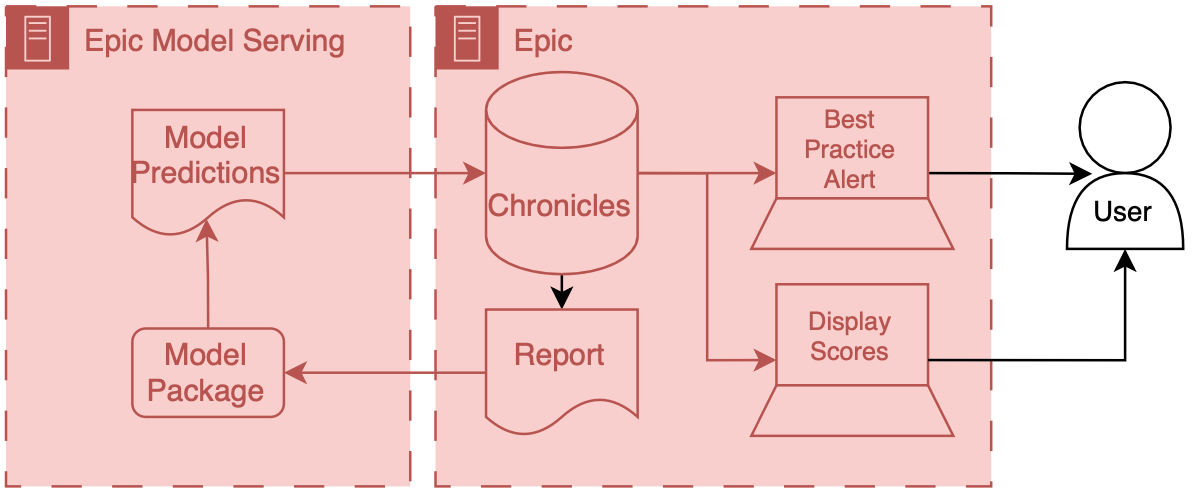
This is the model that we developed to integrated for C. difficile infection risk stratification.
Architecture diagram for implementing custom models served outside of an EMR vendor's system. Research data warehouse generates reports that are then sent to the external model implementation environment, the model generates predictions which are then passed to the EMR system.
Data for this model comes from our research data warehouse then travels to the model posted on a Windows virtual machine.
The predictions from the model are then passed back to the EMR using web services.
We have a report that runs daily from the research state warehouse.
It’s a stored SQL procedure that runs at a set time very early in the morning about 5 AM.
This is essentially a large table of data for each of the patients that were interested in producing a prediction on rows our patients and columns are the various features that were interested in.
Stored procedures update information in a view inside of RDW.
The research data at warehouse and this view are accessible by a Windows machine that we have inside of the health IT secure computing environment.
This windows machine has a scheduled job that runs every morning about at about 6 AM.
This job pull the data down from the database runs a series of python files that you data pre-processing and apply the model to the data to the transform data, and then save the output, model predictions to a shared secured directory on the internal health system network.
We then returned the predictions to Chronicles, using infrastructure that our health IT colleagues helped to develop.
This infrastructure involves a scheduled job written in C# that reads the file that we have saved the shared directory does date of validation and then passes data into chronicles using epics web services framework.
These data end up as flow sheet values for each patient.
We then worked with our epic analyst colleagues to use the flow sheet data to trigger as practice alerts, and also to populate port.
The best practice alerts fire based off of some configuration that’s done inside of epic in order to be able to adjust the alerting threshold outside of Epic what we did was we modified the score such that the alerting information with someone distinct from the actual score so what we did is we packed an alert flag and the score together into a single decimal separated value and this is essentially a number however it’s unique and that it contains two pieces of information so we could take a patient to Oehlert on and we would say 1.56 a patient that we didn’t alert on would be zero point
Model predictions are passed to the EMR system using web services.
Predictions are then filed as either flowsheet rows (inpatient encounters) or smart data elements (outpatient encounters).
You have to build your own infrastructure to push the predictions to the EMR environment.
]]>Erkin ÖtleşHealthcare AI Infrastructure - To be deprecated2024-09-30T00:00:00+00:002024-04-11T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-OverviewNB: this series is still a work in progress.
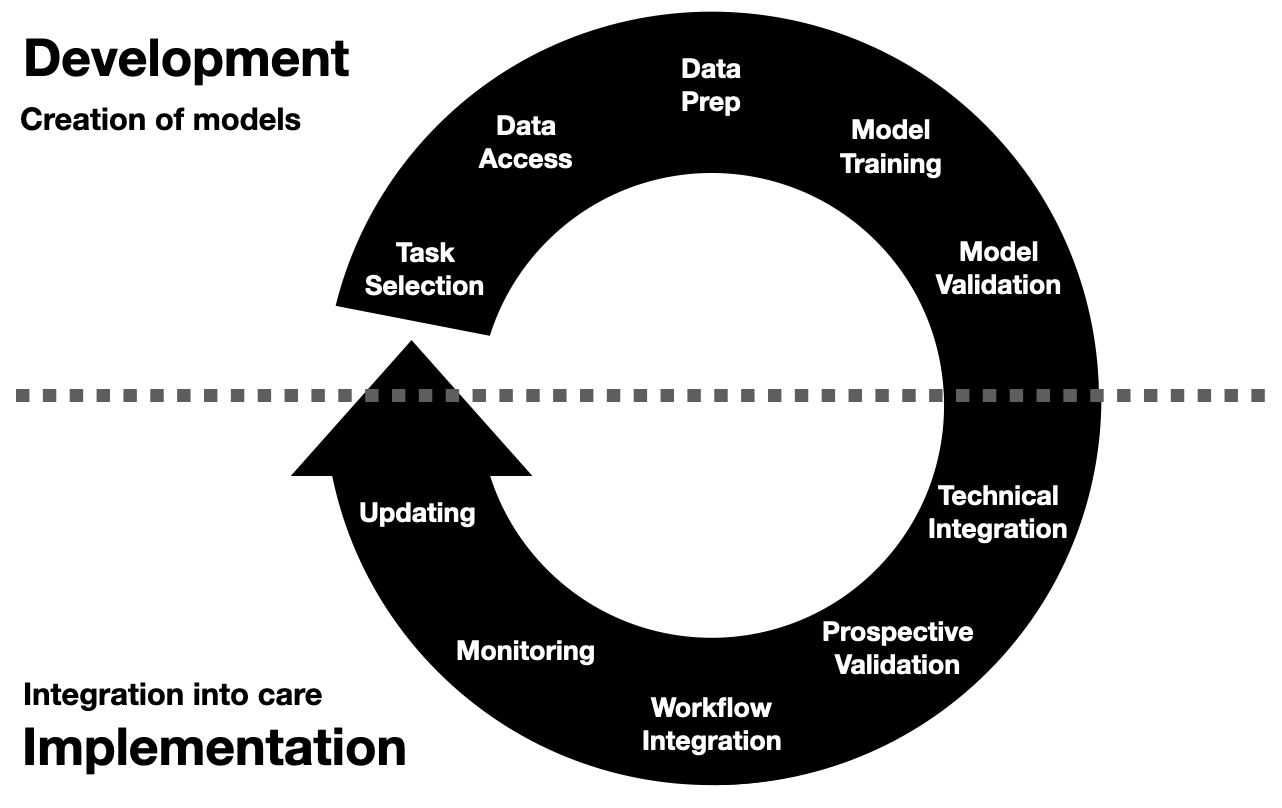
Healthcare AI Infrastructure
This post started as a brief overview of healthcare AI infrastructure and then grew into an unwieldy saga incorporating my perspectives on building and implementing these tools.
As such, I split the post into a couple parts.
This part provides a general introduction, aiming to ground the discussion in the existing HIT landscape and setting up the general approaches for development and implementation.
This post is followed by detailed posts on development and implementation.
In addition to providing more technical details these posts also walk through a couple projects that I’ve taken through the AI lifecycle.
Discussing these projects will make the concepts a bit more concrete.
Basic Healthcare IT Infrastructure
Its important to ground our conversation in the basic healthcare information technology (HIT) infrastructure, primarily focusing on electronic medical records systems (EMRs).
The reason for this is that the EMR is usually the source and destination of information processed by healthcare AI systems.
Having a solid understanding of the parts of the EMR is the foundation to good healthcare AI infrastructure.
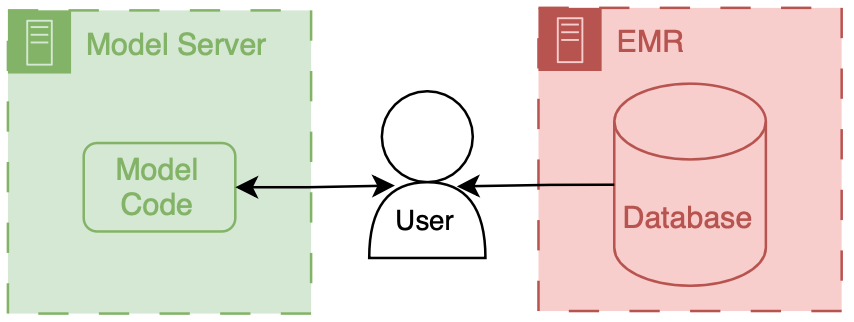
Generic EMR architecture diagram. The EMR backend has an operational database which serve data to clinical users via a client frontend user interface.
You can think of an EMR system as having two main components a database and client.
The database’s primary job is to store the underlying data of the EMR - patient names, demographics, vitals, labs, all the good stuff.
The client’s job is to present the user the information in a way that a human can understand.
There’s a whole bunch of additional code, configuration, and data that we aren’t going to directly discuss, but we may obliquely refer to the amalgamation of that stuff along with our friends the database and client.
The term front end refers to the client and all of its supporting code, configuration, and data handling mechanisms.
Back end refers to the database and all of its supporting configuration and communication code along with any other code that drives the logic and behavior of the EMR.
High-level Epic architecture diagram. Epic has server running a database called Chronicles, which serves data to a front end interface called Hyperspace.
To make things more concrete I’ll briefly discuss the Epic specific names for these components.
Back end: Chronicles
Epic has a large back end written in a programming language called MUMPS (it is also known as M or Caché, which is a popular implementation of the language).
MUMPS is a pretty interesting language for a variety of reasons (integrated key-value database, compact syntax, permissive scoping) - so I might write about it more in the future.
The database management system that holds all of the operational real-time clinical data is called Chronicles, it is implemented using MUMPS for both the data storage and code controlling database logic, schema, indexing, etc.
Front end: Hyperspace
There are several distinct front ends for Epic; however there’s one that’s by far the most important - Hyperspace.
Hyperspace is the big daddy interface that is found on all the computers in clinic and the hospital.
It started out as Visual Basic application (I once heard a rumor that it was the largest piece of software ever made with VB); however, it is now mostly a .NET application.
If you’re a doctor you may also interact with Epic’s other client software, like Haiku (client for mobile phone) and Canto (client for iPad).
Hyperspace is the primary place that clinical work is done, notes are written, orders are placed, and lab values are reviewed here.
These workflows are the primary places where additional contextual information would be helpful or where you would want to serve a best practice alert.
Thus, since Hyperspace is the most likely end-target for most of our healthcare AI efforts.
There are a couple of ways to get information into Hyperspace.
The first is to put stuff into the underlying database, Chronicles, and have the information integrated into the underlying mechanics of the EMR.
The second is to have Hyperspace display a view of the information, but have it served from a different source (like your own web server).
This is usually done through a iframe.1
These options are not limited to Epic EMRs, you should be able to take either approach with any type of modern EMR system.
Now that we have discussed the basic healthcare IT landscape we can start to talk about the specifics of making AI tools for healthcare.
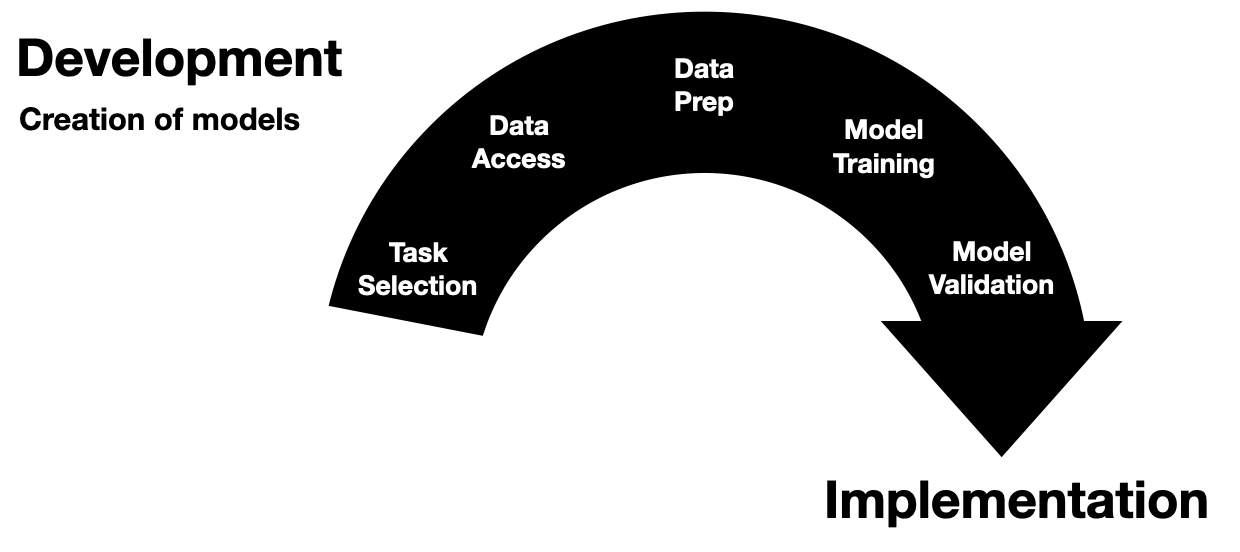
AI Development Infrastructure
Now we can start to dig into the fun stuff - the actual building of healthcare AI models.
At the most basic level you need two things to start building an AI model: data and development environment (a computer).
Data often comes in the form of a report or extract from a database (often the EMR’s database).
This data are then used to train a model using a computing environment that is set up for training models.
These environments tend to be computers that are configured with special software and hardware that allow model developers to write code that can be used to develop and evaluate a model.
The data report out of underlying clinical systems can take a variety of forms.
Their most basic embodiment is that of a simple table of data, where each patient is a row and columns represent different types of info about that patient.
Once you have research or QI access it is pretty straightforward to get extracts of data from the EMR, when working with your local Epic analysts (employed by the hospital) they will probably give you data in the form of an excel or CSV file.
You can also get data from other sources, like collaborative institutions (where you have a shared IRB or BAA) or open source datasets like those available on PhysioNet.
Healthcare AI model development has typically taken place on premises servers that were maintained by the health system or engineering departments capable of attaining HIPAA compliance.
Privacy is super important - worthy of its own set of posts - but we won’t be able to it justice here - so make sure to work with your compliance people to do the right thing.
In terms of software tts fairly standard to use a linux or windows operating system with a python development environment, you usually want to be able to allow python packages to be downloaded as there’s a lot of great open source software out there for this type of work (e.g., scikit-learn , pytorch, tensorflow).
You’ll want to make sure that you have a fairly capable machine (lots of RAM and CPU cores), ideally having access to GPUs will make your life easier as well.
Maintaining all this infrastructure can be pretty difficult, as such there’s been a growing consideration for using cloud-based computing environments.2
Development overview.
The above figure depicts the generic data flow for model development.
Generally the data will flow linearly from a source clinical system towards our model development environment.
To help make the owners of the different components I have employed a consistent color scheme throughout this post.
Everything that is made and maintained by the EMR vendor (or their proxies) is red .
Components owned by AI model developers are colored green .
Components represent shared research infrastructure that may be owned by the health system or research enterprise are blue .
Elements that don’t fit directly in one of these buckets are outlined in black .
Research Infrastructure
Now we can start to talk about the specific infrastructure that you may have to deal with.
This infrastructure is often a shared resource that supports multiple different types of data driven research, like health services research, epidemiology, and multi-omics.
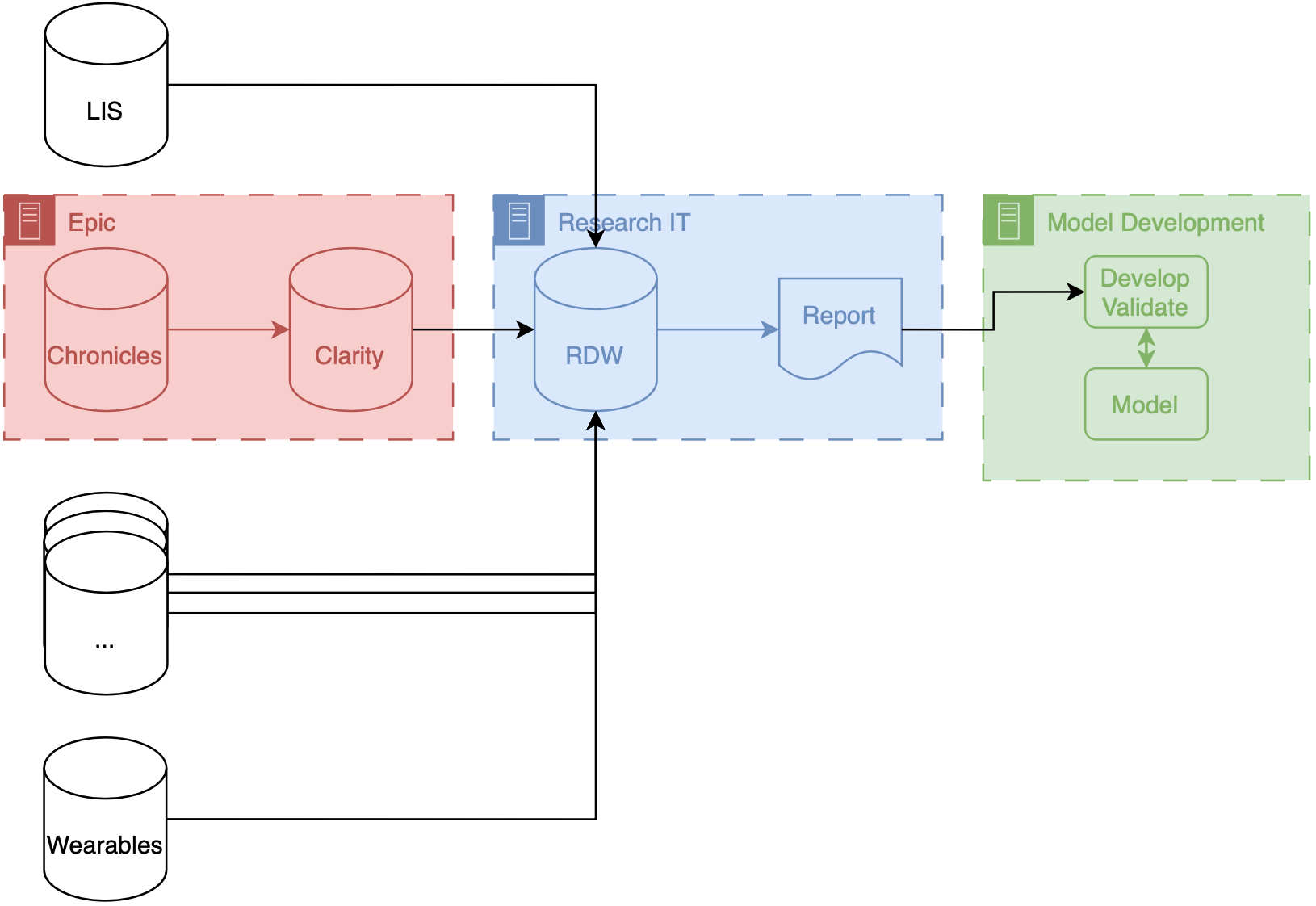
Research infrastructure architecture diagram. Several clinical systems, like the laboratory information system (LIS), EMR, and other sources may get fed into a central research data warehouse (RDW). This is then queried to get reports that can be used to develop models.
If your institution uses Epic your research IT set up may be similar to what we have at Michigan (depicted above).
Our data makes several stops before it gets to model developers.
These stops are known as ETLs (short for extract, transform, load), processes that take data in certain format and convert to another format for entry into a database.
There are two ETLs, the first of which is pretty much mandatory.
Chronicles → Clarity
Chronicles is a database meant to support healthcare operations, but its not optimized for massive queries on large populations of patients.
To offload and optimize these types of analytical queries Epic created Clarity a SQL database (its built using Microsoft SQL Server) that is a transformation of the data stored in Chronicles.
There is an ETL that runs every day that pulls data out of Chronicles and into Clarity.
Clarity → RDW
Some institutions allow researchers to directly access data from Clarity.
That’s not the case at Michigan, instead there is a database that is specifically designed for researchers, known as research data warehouse (RDW).
RDW is also a SQL database and is built on top of CareEvolution’s Orchestrate tooling.
This additional layer imposes some additional transformations but also allows other types of data, such as information from wearables or insurers, to be merged alongside the EMR data.
Data are then queried from RDW and then passed to the model development infrastructure.
The engineers can then work diligently to produce a model.
A note on ETLs
We have found that ETLs may impact the performance of AI models.
There may be subtle differences between the data that come out of an ETL process and the underlying real-time data.
This is a type of dataset shift that we termed infrastructure shift and it means that you can expect slightly worse model performance in these situations.
For more information check out our Mind the Performance Gap paper.
Transitioning from Development to Implementation
As we start to finalize models we end up at the interface between development and implementation.
This interstitial space is tricky because it not only spans a couple steps of the lifecycle, but it also spans different types of infrastructure as well.
I use the arbitrary distinction of technical integration as the demarcating line.
If the model does not yet receive prospective data (not technically integrated) then its still in development.
Much of the discussion from here on out hinges on how the model developer is choosing to implement the model.
We will talk extensively about the choices and the implications in a little bit, but we’ve got to set up the last bit of development for one of these avenues.
Epic Development Infrastructure
If you choose to implementation using Epic’s tooling (or any other vendor’s) you will have to get your model to work on their infrastructure.
This is a wonky space that will likely get better over time.
But in order to do technical integration with Epic you need to test and package your model using a custom development environment that they provide.
I won’t go into a ton of details here, as you’re best served by going to Epic Galaxy to see the latest and greatest documentation.
As a part of model development
Epic provides a Python environment with a load of standard Python AI/ML libraries (…list)
They also provide a couple custom Python libraries that help you interact with the data interfaces.
You can receive tabular data in a JSON structure that is parsed by their libraries
You can then pre-process the data and pass it to your model
Once you have your predictions you packaged up the data using another set of Epic’s Python calls.
Although the development environment is sandboxed, you are not overly constrained in terms of the code you want to include.
You can include additional python and data files in the model package
Additionally you can call external APIs from within this environment if they are whitelisted.
This means that you could include information from other sources or do data processing via another service.
You can take an existing model that was developed in and as long as you use epic approved list of libraries, you can use epic bundling tools to then convert it into a package that can be run on their ECP instance the way that the model receives, data is through a reporting workmen report so you’ll work with your epic analyst to set up a report essentially is the tabular data you want your models received so you specify all the columns and have this done you’ll also have an epic analyst.
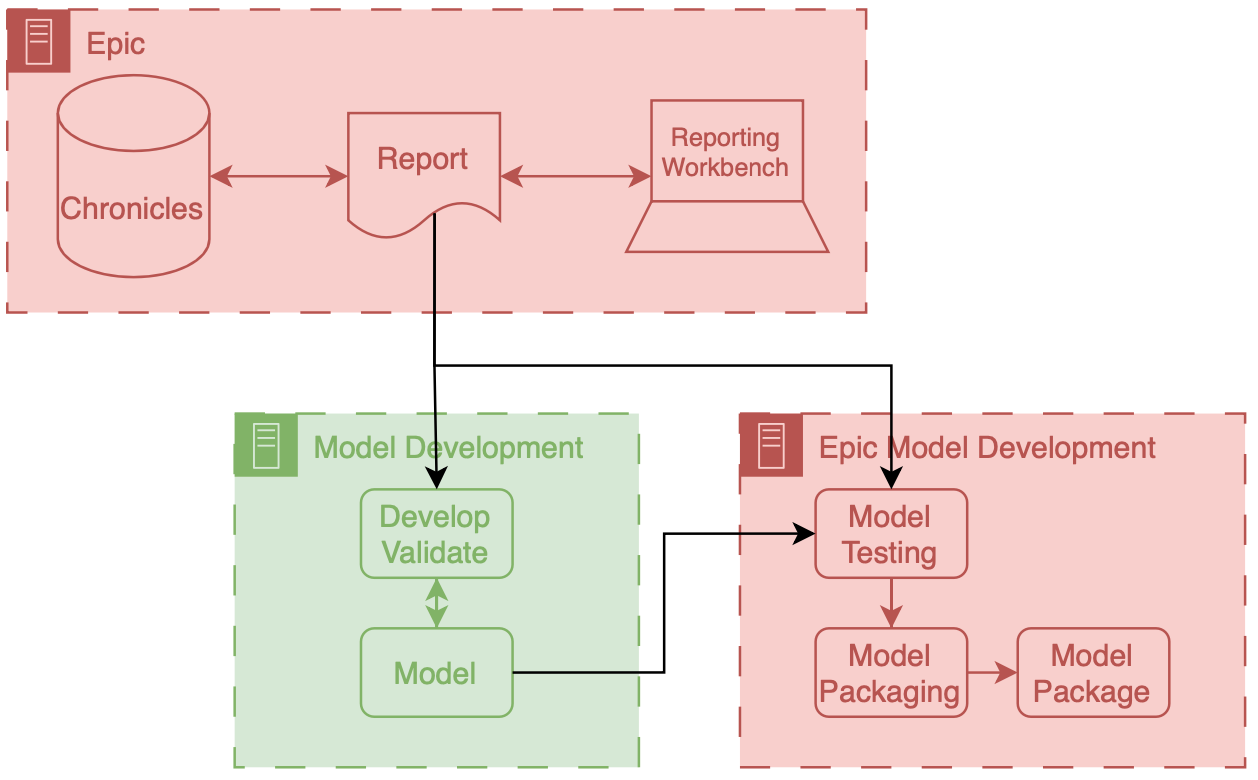
Architecture diagram for developing models inside of an EMR vendor's system. Clinical database generates reports that are then sent to the model development environment, where developers write code for model development and validation which then lead to a model being created. This model is then tested and packaged using the vendor's software. Once tested the model can then be packaged and is ready for implementation.
In this workflow you assess and convert a model that you made with your own infrastructure into a package that can be run on Epic’s implementation infrastructure.
What’s crucial about the workflow depicted above is that there’s a data report that comes directly out of Chronicles (not Clarity) that you use as a part of this packaging workflow.
This is report is often a small extract representing current patients in the health system.
Thus, despite being small it is a very good representation of what the data will look like prospectively, as its generated by the prospective infrastructure.
I think its a really good opportunity to address infrastructure shift, if the model developer uses this data in additional to a larger retrospectively collected research dataset for development.
Maybe I’ll do some research in this direction…
AI Implementation Infrastructure
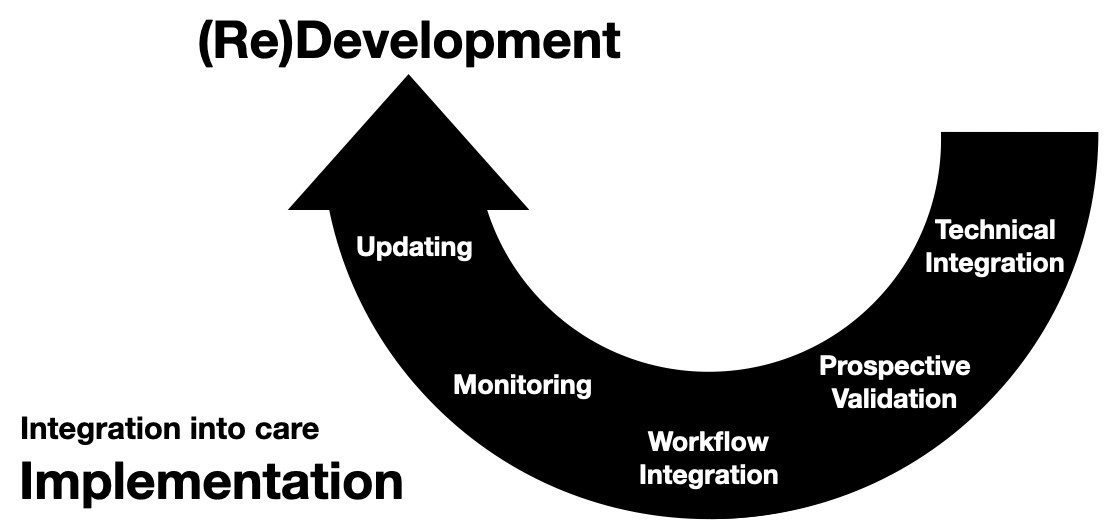
Now we turn our attention to connecting models into care processes, implementation.
As discussed in the previous post, implementation goes beyond the technology, however, the primary focus of this section will be on the implementation step of technical integration, the nuts-and-bolts of connecting AI models to existing HIT systems.
Overview
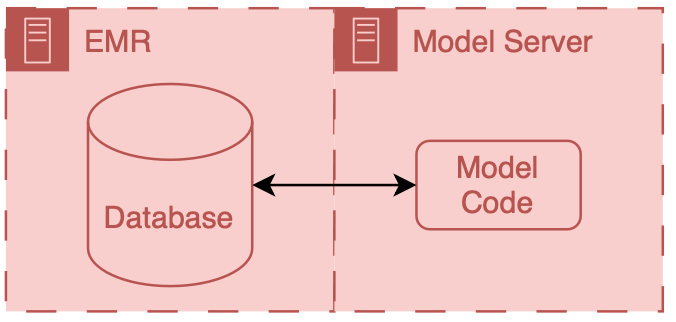
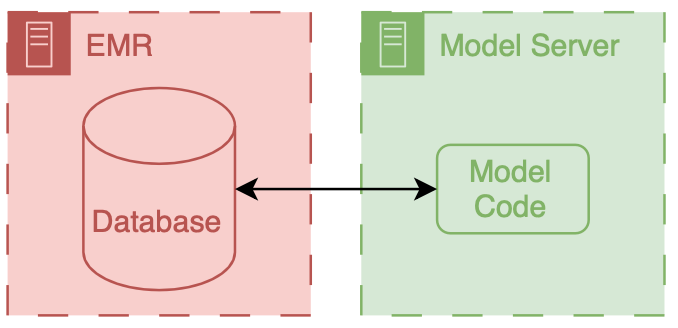
There are two primary ways to integrate a model into existing HIT systems and they are delineated by the relationship to the EMR: internal and external.
Internal integration of models means that developers rely exclusively on the tooling provided by the EMR vendor to do the hosting of the model along with all of the logic around running it and filling the results.
Implementation overview using Epic.
External integration of models means that developers choose to own some of parts of the hosting, running, or filing (usually its the hosting piece).
Implementation overview using self-hosting.
In both scenarios data ends up flowing from the EMR database to the model, however the path that these data take can be drastically different and significant thought should be put into security of the data and the match between the infrastructure and model’s capabilities.
It is important to note that these approaches delegate the display of model results to the EMR system.
They do this by passing model results to the EMR and using EMR tools to display the results to users.
Internal Integration
The infrastructure choices of internal integration are fairly straightforward, as its all dictated by the EMR vendor so you may not have many options.
In the past this would have meant re-programming your model so that it could be called by code in the EMR (e.g., for Epic you would need to have it be a custom MUMPS routine).
Luckily now EMR vendors are building out tools that enable (relatively) easy integration of models.
Limitations
However, there are some major restrictions, because these are not servers that are totally under your control.
Instead they are platforms that are designed to be safe and effective for a variety of use cases.
Thus, they tend to have a couple attributes that may be problematic.
The first is sandboxing, the model code runs in a special environment that has a pre-specified library of code available.
As long as you only use code from that library your model code should function fine, however if you have an additional dependence outside that library you may run into significant issues.
The second is conforming to existing software architectures.
Expanding enterprise software often means grafting existing components together in order to create new functionality.
For example, existing reporting functionality may be used as the starting point for an AI hosting application.
While this makes sense (reporting gets you the input data for your model), it means that you maybe stuck with a framework that wasn’t explicitly designed for AI.
The sandboxing and working with existing design patterns means that square pegs (AI models) may need to be hammered into round holes (vendor infrastructure).
Together this means that you seed a significant amount of control and flexibility.
While this could be viewed as procrustean, it may actually be a good thing as it does force AI models to adhere to certain standards and ensures that there’s a uniform data security floor.
Example
Generally, for this setup you have to a model package and some additional configuration.
The model package contains your model and the code necessary to
package your model in a manner that can be run on the hosting service and that you have additional configuration that determines the data passed to the model
We set up our MCURES project using an internal integration approach.
MCURES was an in-hospital deterioration index tailored for patients admitted to the hospital for acute respiratory failure during the COVID-19 pandemic.
Since we were trying to get this model developed and implemented as fast a possible I chose to go down the internal integration pathway.
Additionally, we started doing the technical integration work in parallel to model development.
At the time we started the MCURES project Epic they offered two options for internal integration:
Epic’s PMML approach is interesting because you essentially specify the model via configuration (using the PMML standard) and Epic builds a copy of the model based on their implementations of different model architectures.
I have not built anything using this approach; however, based on my research at the time it seemed fairly limited, as it supported a small handful of simple model architectures.
Because of the model architecture limitations of PMML we decided to go with ECCP for MCURES.
ECCP enables you to run models in you’ve developed in Python using a proprietary model serving infrastructure.
This model serving infrastructure is essentially a sandboxed Python AI environment hosted using Microsoft Azure.
At a high level data are passed from Chronicles to this special Azure instance, the model produces predictions, which are then passed back to Chronicles.
ECCP takes care of the data transitions and AI developers primarily need to worry about their AI code.
Model input data is passed out of chronicles using reporting workbench.
Reporting workbench is designed for different types of EMR reports.
You can configure special versions of these reports that would pull the necessary data for patients that could be used for an AI model.
Data are in a tabular structure, where rows represent patients or encounters, and columns represent attributes like age, current heart rate, etc..
I won’t go into a ton of details here, but this is the place where you can run into significant limitations, because the underlying data in Chronicles isn’t actually tabular, and the best representation of longitudinal health data is often also not tabular as well so there’s lots of engineering that needs to be done in order to get a good representation of the patients.
Data will then be passed and secure manner to the model, which is running on the special Azure instance.
We talked a little bit about model packaging so we won’t go into that here.
But there is some configuration that is needed when running the model in real time, in addition to the model we need a couple items:
input data report, and
model run information.
We need to explicitly connect the reporting workbench model discussed above to our configuration.
Additionally, we need to instantiate the logic that controls the frequency at which the model runs.
For this one creates a special Epic batch job that will run with a specified frequency.
This job runs the reporting workbench reports and passes that data to the model process that then calculated predictions.
The predictions computed by the model are then passed back to Chronicles.
These end up in special in a special part of the database that’s designed to store predictive model results
The kind of information that you can pass back are a little bit limited because the database is expecting certain types of information.
When the data is back in Chronicles you serve it to users in many different ways.
For example, you could use it to fire best practice alerts or have it be highlighted as an additional column in a list of patients stratify patients based on a risk score.
This is all fairly easy to do because you’ve already been working with your epic analysts to get the data directly into the status structure, and then they can work with their colleagues to set up the best practice alert, or column display.
Despite a couple technical limitations, the entire flow data from Chronicles to ECP and back to Chronicles controlled, unless you have pretty good guarantees about Safety and reliability.
One thing major limitation of this integration approach is that a significant amount of the model run configuration is controlled by health system analysts as opposed to model developers.
This is fine if there is really good communication between the two parties, but there’s often a big disconnect, because analysts sort of sit in a siloed place inside of health system IT And developers tend to be outside of direct health IT and structure.
Usually this ends up devolving into a big game of telephone, as these parties that don’t normally talk to one another or have good relationships.
So, as always, we need to work on this so part of our sociotechnical system.
Architecture diagram for implementing custom models served outside of an EMR vendor's system. Research data warehouse generates reports that are then sent to the external model implementation environment, the model generates predictions which are then passed to the EMR system.
This decision to do technical integration simultaneously with model development turned out to be fairly important.
The learnings from technical integration directly impacted our choices for model development.
For example, we realized that building the reporting workbench report was a relatively laborious process.
Each column in the report took a good amount of time to build and validate.
These columns corresponded to a variable (also known as a feature) that the model took as input.
So the integration effort scaled linearly with the number of features we wanted to include in the model.
During early parts of development we were exploring models with thousands of features, as we had access to the features from RDW and had code to easily manage these features.
However, once we learned more about integration effort we decided to cap the number of features being used to a fairly small number (around 10).
We felt comfortable with this decision because we felt like we hit a good balance between performance and implementation time.
Our early experiments indicated that we wouldn’t lose a ton of performance going from thousands of features to ten (something on the order of less than 10% relative decrease in AUROC) and we were fairly sure that we could implement and test the report with the allocated Epic analyst built time.
External Integration
External integration is the other side of the coin.
Model developers can pick out exactly how they want their model to be hosted and run as well as how they would like it to interface with the EMR.
This additional flexibility is great if you are working on cutting edge research, but it carries a significant burden in terms of guaranteeing that data are handled in a safe and secure manner.
External integration offers a path where innovation can meet clinical applications, allowing for a bespoke approach to deploying AI models.
This flexibility, however, comes with its own set of challenges and responsibilities, particularly in the realms of security, interoperability, and sustainability of the AI solutions.
Limitations
Below are key considerations and strategies for effective external integration of AI in healthcare:
Security and Compliance
When hosting AI models externally, ensuring the security of patient data and compliance with healthcare regulations such as HIPAA in the United States is paramount.
It is essential to employ robust encryption methods for data in transit and at rest, implement strict access controls, and regularly conduct security audits and vulnerability assessments.
Utilizing cloud services that are compliant with healthcare standards can mitigate some of these concerns, but it requires diligent vendor assessment and continuous monitoring.
Interoperability and Data Standards
The AI model must interact with the EMR system to receive input data and return predictions.
Adopting interoperability standards such as HL7 FHIR can facilitate this communication, enabling the AI system to parse and understand data from diverse EMR systems and ensuring that the AI-generated outputs are usable within the clinical workflow.
An alternative is to use a data integration service, like Redox.
Scalability and Performance
External AI solutions must be designed to scale efficiently with usage demands of a healthcare organization.
This includes considerations (that some may consider boring) for load balancing, high availability, and the ability to update the AI models without disrupting the clinical workflow.
Performance metrics such as response time and accuracy under load should be continuously monitored to ensure that the AI integration does not negatively impact clinical operations.
Support and Maintenance
External AI solutions require a commitment to ongoing maintenance and support to address any issues, update models based on new data or clinical guidelines, and adapt to changes in the IT infrastructure.
Establishing clear service level agreements (SLAs) with vendors or internal teams responsible for the AI solution is crucial to ensure timely support and updates.
Example
I’ll detail the external integration of one of our models.
This is the model that we developed to integrated for C. difficile infection risk stratification.
Data for this model comes from our research data warehouse then travels to the model posted on a Windows virtual machine.
The predictions from the model are then passed back to the EMR using web services.
We have a report that runs daily from the research state warehouse.
It’s a stored SQL procedure that runs at a set time very early in the morning about 5 AM.
This is essentially a large table of data for each of the patients that were interested in producing a prediction on rows our patients and columns are the various features that were interested in.
Stored procedures update information in a view inside of RDW.
The research data at warehouse and this view are accessible by a Windows machine that we have inside of the health IT secure computing environment.
This windows machine has a scheduled job that runs every morning about at about 6 AM.
This job pull the data down from the database runs a series of python files that you data pre-processing and apply the model to the data to the transform data, and then save the output, model predictions to a shared secured directory on the internal health system network.
We then returned the predictions to Chronicles, using infrastructure that our health IT colleagues helped to develop.
This infrastructure involves a scheduled job written in C# that reads the file that we have saved the shared directory does date of validation and then passes data into chronicles using epics web services framework.
These data end up as flow sheet values for each patient.
We then worked with our epic analyst colleagues to use the flow sheet data to trigger as practice alerts, and also to populate port.
The best practice alerts fire based off of some configuration that’s done inside of epic in order to be able to adjust the alerting threshold outside of Epic what we did was we modified the score such that the alerting information with someone distinct from the actual score so what we did is we packed an alert flag and the score together into a single decimal separated value and this is essentially a number however it’s unique and that it contains two pieces of information so we could take a patient to Oehlert on and we would say 1.56 a patient that we didn’t alert on would be zero point
Architecture diagram for implementing custom models served outside of an EMR vendor's system. Research data warehouse generates reports that are then sent to the external model implementation environment, the model generates predictions which are then passed to the EMR system.
Model predictions are passed to the EMR system using web services.
Predictions are then filed as either flowsheet rows (inpatient encounters) or smart data elements (outpatient encounters).
You have to build your own infrastructure to push the predictions to the EMR environment.
Bonus: Another Approach to External “Integration”
A great deal of the effort involved in external integration is assuring that the data travels between the EMR and your hosted AI model in a safe and secure manner.
Setting up all the plumbing between the EMR and your system can take the vast majority of your development time.
Let’s say you didn’t want to go through the hassle, but still wanted to enable clinical users to interact with your model.
Well you could provide them with a (secure) way to access your model online and have them be the information intermediaries.
Implementation overview using self-hosting with the user as the intermediary.
This is exactly what MDCalc does.
They have lots of models that physicians can go and input data directly into.
They are super useful clinically, but they’re not integrated into the EMR.
If the amount of data that your model uses is small (a handful of simple data elements), then this could be a viable approach.
And if you don’t collect PHI/PII then you could set up your own MDCalc like interface to your hosted model.
We won’t talk about this architecture in depth, but I think its a potentially interesting way to make tools directly for clinicians.
This can be complicated to do because you need to maintain you own application server and also deal with passing authentication between the EMR session and your application. ↩
I’ve never done a cost break-down analysis for on-premises vs. cloud for healthcare AI research, but I’d love to see results if anyone has some handy. ↩
]]>Erkin ÖtleşM-CURES: AI Infrastructure for Predicting COVID-19 Deterioration in Hospitals2024-09-20T00:00:00+00:002024-09-22T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-MCURES#AI Infrastructure Example: COVID-19 In-Hospital Deterioration
In this post, we dive into a real-world application of healthcare AI infrastructure by exploring the Michigan Critical Care Utilization and Risk Evaluation System (M-CURES).
This project was developed during the early stages of the COVID-19 pandemic to predict in-hospital deterioration for patients suffering from acute respiratory failure.
This post builds on the broader concepts discussed in our previous posts on healthcare AI infrastructure.
If you’re unfamiliar with the foundational ideas behind AI development and implementation, I recommend starting with the introduction to the healthcare AI lifecycle and the technical overview of healthcare AI infrastructure.
These posts lay the groundwork for understanding how AI models are created and integrated into health systems, which will help contextualize the technical decisions made for M-CURES.
This post focuses on our technical integration challenges while implementing M-CURES using Epic’s internal tools and also demonstrates how you can parallelize development and integration.
This parallelization enabled us to move quickly in a fast-moving, high-stakes environment like the early pandemic.
By exploring the infrastructure and workflow that powered M-CURES, we’ll also highlight the importance of collaboration between AI developers and health system analysts.
This post builds off of our previous discussions on healthcare AI infrastructure.
If you are unfamiliar with that infrastructure, reviewing the posts that cover the AI lifecycle or the general infrastructure landscape may be helpful.
The Need: Implement Quickly
In this post, we’ll discuss the technical side of the Michigan Critical Care Utilization and Risk Evaluation System (M-CURES) project.
We developed M-CURES as an in-hospital deterioration prediction system for patients admitted to the hospital for acute respiratory failure during the initial onset of the COVID-19 pandemic.
In the early days of the pandemic, everyone was concerned with quickly triaging patients between different levels of care.
We expected to see a massive influx of patients and wanted to be able to place them in the correct care setting (e.g., home, field hospital, regular hospital, ICU).
To meet this anticipated need, Michigan Medicine leadership asked us to develop and implement a predictive model to help with triage.
We discussed implementation exceptionally early in the project to speed up the process.
Within the first week, we decided to implement the model we developed using Epic’s tools (internal integration).
Although it was our first time using Epic’s tooling, we felt it would give us the best chance at the fastest integration process.
After we decided to go with Epic’s tooling, we started technical integration immediately.
We did this work in parallel with model development to speed up the process as much as possible.
Epic’s Internal Integration Approaches
As mentioned in the development infrastructure post, Epic provides tooling to facilitate internal technical integration.
At the time we started the M-CURES project, Epic offered two options for internal integration:
Epic Cognitive Computing Platform (ECCP) and
Predictive Model Markup Language (PMML).
Epic’s PMML approach is interesting because it implements the model by specifying a model configuration (using the PMML standard).
Epic builds/hosts a copy of the model based on their implementations of different model architectures.
I have not built anything using this approach; however, my research at the time indicated that it was the more limited option, as only a handful of simple model architectures were supported.
Because of the model architecture limitations of PMML, we decided to go with ECCP for M-CURES.
ECCP enables you to host custom Python models using Epic’s model-serving infrastructure.
This model serving infrastructure is a sandboxed Python AI environment hosted using Microsoft Azure.
At a high level, data are passed from Chronicles to this Azure instance; the model runs and produces predictions, which are then passed back to Chronicles.
ECCP takes care of the data transitions, and AI developers primarily only need to worry about their AI code.
Overview of ECCP
Epic's ECCP Implementation Architecture. AI Model serving is closely tied to the EMR functionality. Data transits between two different environments (Epic's regular backend and the Azure environment), but the tight integration between them enables high levels of reliability and makes serving information to users easy.
This infrastructure tightly integrates Epic’s various systems so that data can flow fairly seamlessly from Chronicles to the model and the end user.
Model input data is passed out of Chronicles using Reporting Workbench.
Reporting Workbench is designed for different types of EMR reporting.
Analysts can configure these reports to pull patient data that can be fed to AI models.
Data are in a tabular structure1 where rows represent patients or encounters, and columns represent attributes like age, current heart rate, etc.
These data are then passed securely to the model, which runs on the Azure instance.
The model developer can then include various code and outside data to produce model outputs and related metadata (like explainability scores).
This information is passed back to Chronicles and ends up in a particular part of the database designed to store predictive model results.2
When the data is back in Chronicles, it can be served to users in several ways.
For example, the information could trigger best practice alerts or rank and order a patient list according to risk.
Building alerts and patient lists using the predictions is easy because we are working directly with Epic’s tools.
Throughout the integration process, developers should liaise with health system analysts who are experts in configuring Epic’s systems.
These analysts work with data directly in Chronicles and can then collaborate with their colleagues to set up the best practice alert or column display.
The entire flow of data from Chronicles to ECCP and back to Chronicles is tightly integrated and controlled, which yields good safety and reliability.
Chronicles Not Clarity
What’s crucial about the workflow described above is that there’s a data report that comes directly out of Chronicles (not Clarity) that you use as a part of this packaging workflow.
This report often represents patients currently interacting with the health system (i.e., admitted patients).
By definition, this set of patients/encounters will be much smaller than Clarity’s and other data warehouses’ corpus of retrospective patients/encounters.
However, despite being smaller, it is a nearly perfect representation of what the data will look like prospectively, as the prospective infrastructure generates it and does not undergo any additional transformations.
Sandboxing
ECCP provides a Python environment with a load of standard Python AI/ML libraries (Numpy, Pandas, SKLearn, etc.)
They also offer custom Python functions that help you interact with the data interfaces.
These functions help with:
Receiving inputs: They provide function calls to receive input data exported from Chronicles and parse it into a dataframe.
Returning outputs: After you have model predictions, you can use their function calls to package results and send them back to Chronicles.
These functions help to bookend your model code and help developers automate data flow.
Although the ECCP environment is sandboxed, developers are not constrained in terms of the code they can include, as they can include additional Python and data files in the package.
Additionally, developers can call external APIs within this environment (if the health system’s IT teams safelist them).
External APIs enable developers to include information from other sources or process data via another service.
Thus, converting an existing Python model for use with ECCP is relatively easy.
Model Development
We will now discuss the technical side of how we developed M-CURES using ECCP.
Model development and validation details are in our BMJ paper.
The short version is that model development primarily used Michigan Medicine’s research infrastructure.
Although we obtained most of our training and internal validation data from Michigan Medicine’s Research Data Warehouse (RDW), Epic’s implementation infrastructure reshaped our model development approach.
Architecture diagram for developing models capable of running on ECCP. A crucial part of model development and implementation using ECCP depends on setting up a Reporting Workbench report. This report can improve model development and should be used for validation and packaging.
Reporting Workbench Report
Differences in data pipelines led to a shift in how we built the model.
The research data pipeline we were familiar with for model development gave us a lot of control regarding pulling a wide array of features per patient.
However, this control came at the cost of accessing very low-level data.
We had to put significant development effort into getting the data in the right representational state.
For example, we could easily pull all the meds and vitals for a patient encounter.
But then, it was up to us to figure out how to filter and aggregate these data before feeding it into the model.
Epic’s reporting infrastructure for ECCP can be seen as “higher level,” where the balance between choice and preparation shifts.
The available data through Reporting Workbench reports is limited, but the advantage of automated data filtering and aggregation offsets this restriction.
For example, we can specify that we want the most recent vitals or check whether a patient has received beta-blocker medication.
Another benefit of this approach is that these data elements are standardized across the health system’s Epic reporting infrastructure, so analysts only need to create a column or feature once.
On the whole, this is a great benefit.
However, it does limit the choices available to developers.
Initially, we chafed at this a little.
But this was because we were so used to “rolling our own.”
Standard data components that can be reused and maintained by the health system are the future.
We just weren’t used to it.
We were assigned a small amount of analyst time for the M-CURES project to help build the Reporting Workbench report we would use.
Because this was so limited, we included minimal features in the model.
We selected features by performing several experiments with the training data (from RDW) and routinely checking with our analyst colleagues to ensure we could include them in the report.
Through this iterative process, we ended up with the logistic regression model we wanted to use.
Epic Model Development Environment
At this stage, we had the model weights and Python code.
To run the model in ECCP, we needed to package these components in a format compatible with the sandboxed Azure instance.
This is where Epic’s model development environment, Slate, came into play.
The Slate tooling enables model developers to test and package their Python code.
It’s an Epic-developed docker container replicating the Azure hosting environment.
This environment has a battery of Python libraries commonly used for AI, like Numpy, Pandas, and SKLearn.
It also has custom Epic functions that enable you to test and package the model.
After setting up Slate on our development servers, we ported our logistic regression model to it.
Alongside the code, we also brought in an example report produced by our analyst.
This example report enabled us to use Epic’s tools to conduct aggressive testing.
Using the report, we tested the model with data that closely resembled what it would encounter in production, giving us insight into its real-world performance.
These testing tools enabled us to understand how ECCP worked and debug our model and preprocessing code.
I will describe one of the most valuable tests we conducted in a separate post on technical integration.
Once we were happy with how the model worked in the Slate testing environment, we used Epic’s tools to package the model and all the associated code.
Epic Implementation Environment
We then shared the packaged model with our Epic analyst colleague.
In addition to the model package, there is some configuration that is needed when running the model in real time:
Reporting Workbench report and
model run information.
We connected the Reporting Workbench model discussed above to our configuration.
Additionally, we instantiated the logic that controls the frequency at which the model runs.
Our analysts created an Epic batch job that ran at a specified frequency.3
This job runs the Reporting Workbench reports and passes that data to the model process.
Once you have everything configured, you should be able to monitor the status of previous prediction jobs using Epic’s ECCP management dashboard.
Additionally, analysts can kick off a one-time run of the model.
This is very helpful for debugging, as errors in the Python runtime are displayed in the management dashboard.4
Workflow
After all the setup, our model began producing scores for all the eligible patients in the hospital every couple of hours.
The predictions were filed to Chronicles and displayed as a risk score column for Michigan Medicine’s rapid response team.
This team used the scores to screen patients at higher risk for deterioration.
Final Considerations
Our decision to do technical integration simultaneously with model development was significant.
The learnings from technical integration directly impacted our choices for model development.
For example, building the Reporting Workbench report was relatively laborious.
Each column in the report took a reasonable amount of time to develop and validate.
These columns corresponded to a variable (also known as a feature) the model took as input.
So, the integration effort scaled linearly with the number of features we wanted to include in the model.
During the early stages of development, we explored models with thousands of features, as we had access to the features from RDW and had code to manage these features easily.
However, once we learned more about the integration effort, we decided to cap the number of features used to a small number (around 10).
We felt comfortable with this decision because we could balance performance and implementation time.
Our early experiments indicated that we wouldn’t lose a ton of performance going from thousands of features to ten (something on the order of less than a 10% relative decrease in AUROC), and we were sure that we could implement and test the report with the allocated Epic analywouldn’t time.
One final consideration of the internal integration approach is that a significant amount of the model configuration is outside the direct control of the AI developers.
Instead, a substantial portion of the configuration is under the purview of health system analysts.
This division could be great if there is good communication between the two parties.
However, there’s often a big disconnect.
This disconnect is due to the siloed nature of healthcare IT and AI R&D.
Analysts are siloed inside health system IT, and developers tend to be outside of direct health IT and structure.
Usually, this devolves into a giant game of telephone, as these parties don’t usually talk to one another or have good relationships.
So, as always, we need to work on our sociotechnical system.
We can start by improving communication and tearing down silos.
This is where the non-tabular structure of healthcare data can pose challenges for AI novices. Since the underlying data in Chronicles isn’t organized in a tabular format—and because the best representation of longitudinal health data often isn’t tabular either—significant engineering is required to represent patients more accurately. ↩
The information you can pass back is limited because the database only expects certain types of information (e.g., integer or float). ↩
Care must be exercised with run frequency. I recommend thorough testing before changing the run frequency of a model. ↩
This was a helpful avenue to improve the way my Python code ran in ECCP, as I could write custom exceptions that passed back information about who my code was running. ↩
]]>Erkin ÖtleşHealthcare AI Implementation Infrastructure: Technical Tools for AI Model Integration2024-09-12T00:00:00+00:002024-09-22T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-ImplementationWelcome to the next installment in our healthcare AI infrastructure series.
If you’ve been following along, we’ve already explored the foundational components of healthcare AI in earlier posts, covering the overall AI lifecycle and diving deeper into AI development and implementation processes.
Most recently, we focused on the technical underpinnings of AI development infrastructure and the broader healthcare IT landscape that makes modern AI models possible.
Healthcare AI Implementation Infrastructure
In this post, we shift gears to discuss the nuts and bolts of connecting AI models to real-world clinical workflows, an often overlooked but essential step in the AI lifecycle—implementation.
While development gets a lot of attention, the success of any healthcare AI tool is ultimately determined by how well it integrates into existing health IT systems.
As we explore the technical infrastructure needed to support these implementations, we’ll break down key concepts, such as internal versus external integration, and provide insights into how these choices shape AI deployments’ reliability, flexibility, and security.
A couple of notes before we start.
Although this might not seem that important to the engineers who are on the AI research and development side of things, I would argue that understanding the downstream will not only increase your success of projects eventually making a clinical impact but also that there are exciting and cool research ideas that can come out of thinking about development.
Although the implementation goes beyond the technology, this section primarily delves into the ‘nuts-and-bolts’ of the implementation step, known as technical integration. This is the process of connecting AI models to existing HIT systems.
By the end of this post, you’ll have a clearer understanding of the infrastructure choices that impact the successful implementation of healthcare AI models and how to navigate the complexities of this critical phase in the AI lifecycle.
Our goal is to provide you with the knowledge and insights you need to make informed decisions in your healthcare AI projects.
Two Approaches to Implementation
Before we delve into the details, it’s important to understand the two main approaches to integrating a model into health IT systems.
These are categorized as internal or external based on their relationship to the EMR.
Internal integration of models means that developers rely exclusively on the tooling provided by the EMR vendor to host the model along with all of the logic around running it and filing the results.
Implementation overview using Epic.
External integration of models means that developers choose to own some parts of the hosting, running, or filing (usually the hosting piece).
Implementation overview using self-hosting.
In both scenarios, data flows from the EMR database to the model.
However, the path these data take can be drastically different, and significant thought should be put into the security of the data and the match between the infrastructure and the model’s capabilities.
It is important to note that these approaches delegate the display of model results to the EMR system.
They do this by passing model results to the EMR and delegating user displays to existing EMR tools.
Internal Integration
The infrastructure choices for internal integration are pretty straightforward; they are all dictated by the EMR vendor, so you might not have any options.
In the past, this would have meant re-programming your model to be called by code in the EMR (e.g., for Epic, you would need to have it be a custom MUMPS routine).
Luckily, EMR vendors are now building out tools that enable (relatively) easy integration of models.
Architecture diagram for implementing custom models served outside an EMR vendor's system. Research data warehouse generates reports sent to the external model implementation environment, and the model generates predictions that are then passed to the EMR system.
Limitations
However, some major restrictions exist because these servers are not totally under your control.
Instead, they are platforms designed to safely and effectively support a myriad of clinical use cases.
Thus, they have a couple of attributes that may be problematic.
The first attribute is sandboxing; the model code runs in a special environment with a pre-specified code library available.
As long as you only use code from that library, your model code should function fine.
However, you may run into significant issues if you have an additional dependence outside that library.
The second is conforming to existing software architectures.
Expanding enterprise software often means grafting existing components together to create new functionality.
For example, existing reporting functionality may be used as the starting point for an AI hosting application.
While this makes sense (reporting gets you the input data for your model), you may be stuck with a framework that wasn’t explicitly designed for AI.
The sandboxing and working with existing design patterns means that square pegs (AI models) may need to be hammered into round holes (vendor infrastructure).
Together, this means that you seed a significant amount of control and flexibility.
While this could be viewed as procrustean, it forces AI models to adhere to specific standards and ensures a uniform data security floor.
External Integration
External integration offers the opposite approach.
Model developers can choose how their model is hosted and operates and how it interfaces with the EMR.
This flexibility is especially valuable for cutting-edge research.
However, it also comes with the significant responsibility of ensuring that data is handled safely and securely.
External integration offers a path where innovation can meet clinical applications, allowing for a bespoke approach to deploying AI models.
This flexibility, however, comes with its own set of challenges and responsibilities, particularly in the realms of security, interoperability, and sustainability of AI solutions.
Architecture diagram for implementing custom models served outside of an EMR vendor's system. Research data warehouse generates reports sent to the external model implementation environment, and the model generates predictions that are then passed to the EMR system.
Limitations
Below are key considerations and strategies for effective external integration of AI in healthcare:
Security and Compliance
When hosting AI models externally, ensuring the security of patient data and compliance with healthcare regulations such as HIPAA in the United States is paramount.
It is essential to employ robust encryption methods for data in transit and at rest, implement strict access controls, and regularly conduct security audits and vulnerability assessments.
Utilizing cloud services compliant with healthcare standards can mitigate some of these concerns, but diligent vendor assessment and continuous monitoring are required.
Interoperability and Data Standards
The AI model must interact with the EMR system to receive input data and return predictions.
Adopting interoperability standards such as HL7 FHIR can facilitate this communication, enabling the AI system to parse and understand data from diverse EMR systems and ensuring that the AI-generated outputs are usable within the clinical workflow.
An alternative is to use a data integration service like Redox.
Scalability and Performance
External AI solutions must be designed to scale efficiently with the usage demands of a healthcare organization.
This includes considerations (that some may consider boring) for load balancing, high availability, and the ability to update the AI models without disrupting the clinical workflow.
Performance metrics such as response time and accuracy under load should be continuously monitored to ensure that the AI integration does not negatively impact clinical operations.
Support and Maintenance
External AI solutions require a commitment to ongoing maintenance and support to address any issues, update models based on new data or clinical guidelines, and adapt to changes in the IT infrastructure.
Establishing clear service level agreements (SLAs) with vendors or internal teams responsible for the AI solution is crucial to ensure timely support and updates.
Bonus: Another Approach to External “Integration”
Safety and security can be a significant obstacle to external integration.
Setting up the necessary connections and infrastructure between the EMR and your system can consume most of your development time.
If you wanted to avoid the complexity of full integration but still allow clinical users to interact with your model, you could offer them a secure online interface.
In this setup, the users act as intermediaries, manually inputting and retrieving information from the model.
Implementation overview using self-hosting with the user as the intermediary.
MDCalc follows this approach, offering numerous models for physicians to input data directly.
These tools are handy in clinical practice but not integrated into the EMR.
If the amount of data your model uses is small (a handful of simple data elements), this could be a viable approach.
If you don’t collect PHI/PII, you could set up your own MDCalc-like interface for your hosted model.
We won’t discuss this architecture in-depth, but it’s an exciting way to make tools directly for clinicians.
Parting Thoughts
In choosing between internal and external integration for healthcare AI models, you must weigh the benefits and limitations of each approach.
Internal integration offers simplicity and security by operating within the confines of existing EMR systems, but this comes at the cost of flexibility.
External integration provides greater control and customization, which can be invaluable for cutting-edge AI tools, but this flexibility comes with increased responsibility for security, compliance, and interoperability.
Ultimately, the decision between these approaches hinges on your specific needs—whether you’re focused on rapid deployment with minimal disruption or seeking a more customized, innovative solution that can push the boundaries of what’s possible.
Looking Ahead
The infrastructure supporting these systems must adapt as healthcare AI continues to evolve.
With increasing pressures on health systems to integrate advanced AI solutions, understanding the nuances of technical integration will be critical for success.
The ability to connect models to clinical workflows effectively, ensure data security, and maintain operational efficiency will separate successful AI projects from those that never make it to the bedside.
In the next few blog posts, I’ll dive deeper into some real-world applications and examples of how these concepts play out.
I’ll explore our C. difficile infection model integration, the M-CURES system for COVID-19 deterioration, and best practices for technical integration testing.
These case studies will provide more concrete examples of the challenges and solutions that arise when moving from theory to practice.
Whether you’re developing a new AI tool or preparing to integrate one into your health system, remember that implementation is not just about technology—it’s about aligning people, processes, and tools to ensure that AI improves patient care.
]]>Erkin ÖtleşHealthcare AI Development Infrastructure: Tools and Data for Model Creation2024-09-11T00:00:00+00:002024-09-22T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-Infrastructure-DevelopmentHealthcare AI Development Infrastructure
This post introduces several tools for developing healthcare AI models.
Although AI models can be developed in isolation and implemented later, it’s more effective to approach development and implementation as interconnected processes.
Projects are more successful when this connection is recognized, as most healthcare AI initiatives fail during implementation.
These failures often stem from neglecting the constraints imposed by real-world applications.
By understanding implementation challenges early on and designing with them in mind, you significantly increase the chances of success when it’s time to deploy the model.
While this post focuses on development, it’s written from the perspective of someone who has been through the entire process many times.
I encourage you to read the upcoming post on implementation as well so you can fully understand the lifecycle before beginning your journey.
Overview
As mentioned in the last post, two key components are needed to build a model: data and a development environment (a computer).
Data often comes from clinical databases, such as those in an EMR or other clinical systems.
Once obtained, this data is transferred to computing environments designed specifically for model development, typically equipped with specialized software and hardware.
Overview of model development. Data are extracted from clinical systems, like the EMR. These data are then transferred to model development environments, where engineers can write code that they use to develop and validate AI models.
The above figure depicts the environments and data flows between them for model development.
It’s straightforward, with data being extracted from the clinical system and then moved into a model development environment, where most development work is done.
Data
Data extracted from clinical systems can take many forms, with the most basic being a simple table where each row represents a patient and each column contains different types of information about them.
Once you have research or quality improvement (QI) access, obtaining data from the EMR is relatively straightforward. When collaborating with your local Epic analysts (typically employed by the hospital), they will likely provide the data in Excel or CSV files.
You can also access data from other sources, such as collaborative institutions (with shared IRB or BAA agreements) or open-source datasets like those available on PhysioNet.
Development Environments
Healthcare AI model development typically occurs on on-premises servers maintained by the health system or engineering departments that can ensure HIPAA compliance.
Privacy is crucial—and deserves a dedicated post—suffice it to say that it’s essential to collaborate with your compliance and security teams to handle privacy correctly.
Regarding software, using a Linux or Windows operating system with a Python development environment is common.
You’ll want to enable access to Python packages via a package/environment manager (like PyPi or Anaconda) since there’s a wealth of excellent open-source tools for this work (e.g., scikit-learn, PyTorch, TensorFlow).
A powerful machine with plenty of RAM and CPU cores is essential; access to GPUs will significantly speed up your work.
Maintaining this infrastructure can be complex, which is why many are increasingly turning to cloud-based computing environments for these tasks1
Research Infrastructure
Now, we can discuss the specific infrastructure you may have to deal with.
This infrastructure is often a shared resource supporting multiple types of data-driven research activities, such as health services research, epidemiology, and multi-omics.
Research infrastructure architecture diagram. Several clinical systems, like the laboratory information system (LIS), EMR, and other sources, may get fed into a central research data warehouse (RDW). RDW is then queried to get reports that can be used to develop models.
If your institution uses Epic, your research IT setup may be similar to what we have at Michigan (depicted above).
Our data makes several stops before it gets to model developers.
These stops are known as ETLs (short for extract, transform, load), processes that take data in a specific format and convert it to another format for entry into a database.
There are two ETLs, the first of which is essentially mandatory.
Chronicles → Clarity
Chronicles is a database meant to support healthcare operations, which means it’s excellent at enabling the millions of transactions needed daily for patient care.
But it’s not optimized for massive queries on large populations of patients.
To offload and optimize these types of analytical queries, Epic created Clarity, a SQL database (built on top of SQL products like Microsoft SQL Server and Oracle Database) that is a transformation of the data stored in Chronicles.
There is an ETL that runs every day that pulls data out of Chronicles and into Clarity.
Clarity → RDW
Researchers can access data directly from Clarity at some institutions, but that’s not the case at Michigan.
Instead, a dedicated database for researchers, known as the research data warehouse (RDW), is used.
RDW is an SQL database built on CareEvolution’s Orchestrate platform.
This additional layer introduces some transformations but also enables the integration of other data types, such as wearable or insurer data, alongside EMR data.
Once data is queried from the RDW, it is transferred to the model development infrastructure, where engineers can work meticulously to build the model.
A note on ETLs
We have found that ETLs can impact the performance of AI models.
There may be subtle differences between the data produced by an ETL process and the underlying real-time data.
These differences are a form of dataset shift that we refer to as infrastructure shift.
You can generally expect slightly reduced model performance when implementing models developed using data that have undergone ETL processes.
For more information, check out our Mind the Performance Gap paper.
The Interface Between Development and Implementation
As we finalize models, we enter the interface between development and implementation.
This transitional phase is tricky because it spans not only multiple steps in the lifecycle but also different types of infrastructure.
I use the arbitrary distinction of technical integration as the dividing line: if the model is not yet receiving prospective data (i.e., it’s not technically integrated), it remains in development.
From here on, much of the discussion depends on how the model developer implements the model.
We will save most of this discussion for upcoming posts.
However, we will quickly discuss the final stages of development necessary for projects that choose to implement using an EMR’s internal integration tooling.
Epic Development Infrastructure
If you decide to implement using Epic’s platform (or another vendor’s), you must ensure your model works on their infrastructure.
AI-EMR internal integration is a complex area that will likely improve over time.
However, to integrate technically within Epic, you’ll need to test and package your model using their custom development environment.
I won’t dive into the details here, as your best resource is Epic Galaxy for the most up-to-date documentation.
As part of model development, Epic provides a Python environment equipped with standard AI/ML libraries (e.g., NumPy, Pandas, scikit-learn). They also offer custom Python libraries to facilitate interaction with their data interfaces.
You can receive tabular data in a JSON format, which their libraries parse for you.
After pre-processing the data, you can pass it to your model.
Once your model generates predictions, you package them back to the EMR using another set of Epic’s Python functions.
Although the development environment is sandboxed, you are not overly constrained in the code you want to include.
You can include additional Python and data files in the model package
Additionally, you can call external APIs from within this environment if your organization safelists them.
External API calls enable you to include information from other sources or to process data via another service.
Architecture diagram for developing models within an EMR vendor's system. A clinical database generates reports, which are sent to the model development environment. In this environment, developers write code for model development and validation, leading to the creation of the model. The model is then tested and packaged using the vendor's software. Once tested, the model is packaged and ready for implementation.
In this workflow, you take a model developed in your infrastructure and convert it into a package that can be run on Epic’s implementation infrastructure.
A vital aspect of the workflow shown above is using a data report that comes directly from Chronicles (not Clarity) as part of this packaging process.
This report is typically a small extract representing current patients in the health system.
While small, it provides a highly accurate representation of prospective data since it is generated by the same infrastructure.
This small report creates a valuable opportunity to address infrastructure shift by using this real-time data alongside a more extensive, retrospectively collected research dataset during development. I think this approach could be worth exploring further—I might even consider researching this in the future.
Wrapping Up
In this post, we’ve covered the foundational aspects of healthcare AI model development, briefly touching on data acquisition and development environment setup.
This brief discussion on the intersection of development and implementation highlights a key recurring theme: the importance of foresight and integrated planning in AI projects.
By understanding how data is handled, transformed, and utilized throughout the process, developers can better anticipate the practical challenges that emerge during model implementation.
This proactive approach streamlines the transition from development to deployment and improves the adaptability and effectiveness of the solutions we create.
In the next post, we will cover the infrastructure required to support AI implementation. Learn more in the AI Implementation Infrastructure post.
I’ve never done a cost breakdown analysis for on-premises vs. cloud for healthcare AI research, but I’d love to see results if anyone has some handy. ↩
]]>Erkin ÖtleşHealthcare AI Infrastructure: Key Systems for Making & Using Clinical AI Models2024-09-10T00:00:00+00:002024-09-22T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-InfrastructureHealthcare AI Infrastructure
For a general overview of the healthcare AI lifecycle, check out the introductory post.
This post started as a brief overview of healthcare AI infrastructure and then grew into an unwieldy saga incorporating my perspectives on building and implementing these tools.
As such, I split the post into a couple of parts.
In this post we will review the existing HIT landscape and provide a general set of approaches for development and implementation.
This’ll be followed by detailed posts on development and implementation.
These posts provide more technical details and discuss a couple of projects I’ve shepherded through the AI lifecycle.
Additionally, this series will focus on AI models that interact with electronic medical records (EMR) and related enterprise IT systems used by health systems.
This focus is partly due to my expertise—I worked for an EMR vendor and have built and deployed several models in this setting.
However, it is also a natural interaction point.
We connect AI models with EMRs because EMRs are the software systems most closely tied to care delivery.
Given this framing, we will now lay out the significant components.
Basic Healthcare IT Infrastructure
Let’s start by grounding our conversation on the most fundamental healthcare information technology (HIT) infrastructure component: electronic medical records systems (EMRs).
We will focus on EMRs because they are often the source and destination of information processed by healthcare AI systems.
A solid understanding of the subcomponents of the EMR is necessary for creating healthcare AI infrastructure.
Generic EMR architecture diagram. The EMR backend has an operational database that serves data to clinical users via a client frontend user interface.
You can think of an EMR system as having two main components: a database and a client.
The database’s primary job is to store the EMR’s underlying data—patient names, demographics, vitals, labs, notes, and any other necessary clinical data.
The client’s job is to present the information in a way that the user can understand.
There’s a lot of additional code, configuration, and data that we won’t discuss directly, but these supporting artifacts help to round out the functionality of the database and the client.
There are special names for these amalgamations: front end and back end.
The term front end refers to the client and its supporting code, configuration, and data handling mechanisms.
Back end refers to the database and all of its supporting configuration and communication code, along with any other code that drives the logic and behavior of the EMR.
High-level Epic architecture diagram. Epic has a server running a database called Chronicles, which serves data to a front end interface called Hyperspace.
To make things more concrete, we will briefly discuss the Epic-specific names for these components.
Back end: Chronicles
Epic has a large back end written in a programming language called MUMPS (it is also known as M or Caché, which is a popular implementation of the language).
MUMPS is an interesting language for various reasons (integrated key-value database, compact syntax, permissive scoping).
So I might write about it more in the future, but Aaron Cornelius has some nice posts on the vagaries of MUMPS code.
The database management system that holds all of the operational real-time clinical data is called Chronicles, it is implemented using MUMPS for both the data storage and code controlling database logic, schema, indexing, etc.
Front end: Hyperspace
There are several distinct front ends for Epic; however, one is by far the most important: Hyperspace.
Hyperspace is the big daddy interface found on all the computers in the clinic and the hospital.
It started life as a Visual Basic application (I once heard a rumor that it was the largest Visual Basic application ever made); however, it is now primarily a .NET application.
If you’re a doctor, you may also interact with Epic’s other client software, such as Haiku (a mobile phone client) and Canto (an iPad client).
There’s also MyChart, a front end that enables patients to review their records and communicate with their healthcare team.
Hyperspace is the primary place where clinical work is done.
It is where notes are written, orders are placed, and lab values are reviewed.
These workflows are the primary places where additional contextual information is helpful or where you want to serve a best practice alert.
Thus, Hyperspace is the most likely end-target for most of our healthcare AI efforts.
There are a couple of ways to get information into Hyperspace.
The first is to insert data into the underlying database, Chronicles, and integrate the information into the EMR’s underlying mechanics.
The second is to have Hyperspace display a view of the information but serve it from a different source (like your own web server).
This is usually done through a iframe.1
These options are not limited to Epic EMRs; you should be able to take either approach with any modern EMR system.
Now that we have discussed the basic healthcare IT landscape, we can start to discuss the specifics of making AI tools for healthcare.
AI Development Infrastructure
Now, we can start to dig into the fun stuff - the actual building of healthcare AI models.
To start building an AI model, you need two things: data and a development environment (a computer).
Data often comes in the form of a report or extract from a database (usually the EMR’s database).
These data are then used to train a model using a computing environment set up for this purpose.
These environments tend to be configured with special software and hardware, which allow model developers to write code to develop and evaluate a model.
Architecture of development. Data comes from the EMR and is then transferred to development environments (usually in the form of reports).
The above figure depicts the generic data flow for model development.
Generally, the data will flow linearly from a source clinical system to our model development environment.
AI Implementation Infrastructure
Now we focus on connecting models into care processes, implementation.
As discussed in the previous post, implementation goes beyond the technology, however, the primary focus of this section will be on the implementation step of technical integration, the nuts-and-bolts of connecting AI models to existing HIT systems.
There are two primary ways to integrate a model into existing HIT systems, and the relationship to the EMR delineates them as internal and external.
Internal integration of models means that developers rely exclusively on the tooling provided by the EMR vendor to host the model along with all of the logic that controls the running of the model and filing of its results.
Internal integration. Model runs on services provided by the EMR vendor. Data doesn't leave environment secured by vendor.
External integration of models means that developers own some parts of the hosting, running, or filing (usually the hosting piece).
External integration. Model runs on services external to the EMR and data are passed back and forth.
In both scenarios, data flows from the EMR database to the model; however, the path these data take can be drastically different, and significant thought should be put into the security of the data and the match between the infrastructure and the model’s capabilities.
It is important to note that these approaches delegate the display of model results to the EMR system.
They do this by passing model results to the EMR and using EMR tools to display the results to users.
A Note on Color Coding
Throughout this series, I have employed a consistent color coding scheme to identify the owners of different HIT components.
Everything made and maintained by the EMR vendor (or their proxies) is red .
Components owned by AI model developers are colored green .
Components that the health system or research enterprise may own are blue .
Elements that don’t fit directly in one of these buckets are outlined in black .
What’s next?
Because it’s a shiny new toy, healthcare AI can sometimes seem like it should be in a class of its own compared to existing technologies.
This is absolutely not the case; good healthcare AI is good HIT.
I think there is no real distinction between HIT and healthcare AI because they interact with the same data and users.
A comprehensive understanding of EMRs and associated clinical care systems is paramount in developing and implementing healthcare AI models.
This post is followed by detailed posts on AI development infrastructure and implementation infrastructure.
This can be complicated because you need to maintain your own application server and also deal with passing authentication between the EMR session and your application. ↩
]]>Erkin ÖtleşHealthcare AI Implementation: Steps for Successful Clinical Integration2024-09-03T00:00:00+00:002024-09-20T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-ImplementationYou’ve developed an AI model that could “revolutionize” patient care—but how do you ensure it truly impacts the clinical workflow and improves outcomes?
This is where implementation becomes paramount.
Implementing Healthcare AI
This post builds off of a previous introduction to the healthcare AI lifecycle and a discussion on healthcare AI development.
These are not necessary pre-reading, but they provide a good background for the main focus of this post: Implementation
Implementation is the work of integrating and utilizing an AI model into clinical care.
This post will first cover key implementation steps and general challenges associated with implementing AI tools in healthcare.
Healthcare AI implementation portion of the lifecycle. Implementation is the integration of models into workflows and generally has the following steps: technical integration, prospective validation, workflow integration, monitoring, and updating.
Implementation Steps
Like the development process, I break down implementation into five steps.
Technical Integration
Prospective Validation
Workflow Integration
Monitoring
Updating
There may be some non-linearity and blurring of these steps; however, implementation tends to work better the more structured this process is.
That’s because there’s more “on the line” the further along the lifecycle you get.
So, it’s best to be sure you’ve perfected a step before moving on to the next.
Technical Integration
Technical integration is the first step, and it involves getting the AI model to communicate with existing healthcare IT systems.
Model developers will need to work closely with IT departments to ensure that data can flow smoothly (and securely) from care systems, such as electronic medical records (EMRs), to the AI model and back.
Significant effort will need to be expended at this stage.
Although model developers and healthcare IT (HIT) administrators are technically inclined, they may need help working together initially due to their focus on different technologies and differing priorities.
Thus, it can take a lot of work for a model developer to explain the needs of their model, and HIT administrators may need to expend additional effort to make their existing technology stacks compatible with AI models.
I’ll have several blog posts detailing some technical approaches, but it’s important to note that all of these steps are complex socio-technical processes.
We should push to use a layer of technology standards, like FHIR, but we should also develop good governance and processes around technical integration.
Finally, technical integration must be conducted before assessing whether an AI model will work well for a given health system.
That’s because the model’s performance isn’t truly known until it starts running in situ.
Prospective Validation
Prospective validation is the first high-fidelity test of the model.
It’s about running the model in the real world but in a controlled manner.
The aim is to see how the model performs with live data without directly impacting patient care.
This step is critical for assessing the model’s readiness for full-scale implementation and identifying any unforeseen issues that might not have been apparent during development.
I recommend that all model developers and implementers aim to conduct a silent prospective validation, which is where the model’s predictions are tested in a live clinical data environment without affecting clinical decisions (scores/alerts are not shown to users).
Prospective validation is sometimes the only way to assess if your model development and technical integration worked correctly.
We did a deep dive into an AI model we developed and implemented for the health system.
This work is cataloged in the Mind the Performance Gap: Dataset Shift During Prospective Validation paper.
In addition to discussing prospective validation, we uncovered a new type of dataset shift driven primarily by issues in our health IT infrastructure.
The difference between the data our model saw during development and implementation environments caused a noticeable degradation in performance.
So, we needed to rework our model and the technical integration to ameliorate this performance degradation.
Workflow Integration
Integrating an AI model into clinical workflows is more art than science.
Fundamentally, you need to understand how healthcare professionals work, what information they seek, and when they need it.
Ultimately, we want AI tools to fit into physician routines and not disrupt them.
The default has been to “alert” clinicians by sending a push of information as a page or pop-up (best practice alert).
While these may have a place in some workflows, I find them particularly irksome in my daily practice as they tend to break my mental flow.
We should push for other ways to integrate the outputs of AI tools into our workflows.
One approach might involve designing intuitive user interfaces for clinicians or setting up alert systems that are less disruptive but still provide actionable insights.
For example, it would be great if there was a chat-like interface that enabled AI tools to ping me with messages that were previously BPAs.
I could work through these messages and query the AI system with follow-up questions.
Monitoring
The job isn’t over once an AI model is up and running.
Continuous monitoring ensures the model remains performant and relevant over time.
This process involves tracking the model’s performance, identifying any drifts in accuracy, and being alert to changes in clinical practices that might affect how the model should be used.
Keeping track of basic model performance statistics, such as the number of alerts, sensitivity, and positive predictive value, can be challenging.
That is because we need better infrastructure to do this automatically.
So even if a model developer completes all the implementation work, they may have to manually set up all the logging necessary to collect all these statistics.
Hopefully, this will become easier as we develop more robust tools, like Epic’s Seismometer.
It would be great to transcend beyond basic monitoring.
I imagine a future in which AI tool users can provide real-time performance feedback, and developers can use that feedback to improve models.
Updating
You don’t “set it and forget it” with AI models in healthcare.
Models must be maintained as medical knowledge advances and patient populations change.
Updating models might involve:
retraining with new data,
incorporating feedback from users, or
Redesigning the model to accommodate new clinical guidelines or technologies.
Ensuring models remain current and relevant involves more than just routine retraining with new datasets.
It demands a thoughtful approach, considering how updates might impact the user’s trust and the model’s usability in clinical settings.
This challenge is where our recent work on Updating Clinical Risk Stratification Models Using Rank-Based Compatibility comes into play.
We developed mathematical techniques to ensure that updated models maintain the correct behavior of previous models that physicians may have come to depend on.
Updating models to maintain or enhance their performance is crucial, especially as new data become available or when data shifts occur.
However, these updates must maintain the user’s expectations and the established workflow.
Our research introduced a novel rank-based compatibility measure that allows us to evaluate and ensure that the updated model’s rankings align with those of the original model, preserving the clinician’s trust in the AI tool.
Challenges
Implementing AI models into clinical care can be challenging.
During model implementation, the goal is to use models to estimate unknown information that can be used to guide various healthcare processes.
This real-world usage exposes models to the transient behaviors of the healthcare system.
Over time, we expect the model’s performance to change.
Even though the model in use may not be changing, the healthcare system is, and these changes in the healthcare system may reflect new patterns that the model was not trained to identify.
Contrasting this with the fact that the model may also change over time is essential.1
Although we often talk about static models (which model developers may update occasionally), it is important to note that some are inherently dynamic.
These models change their behavior over time.
Employing updating and dynamic models produces a second set of factors impacting how a model’s performance could change over time.
Thus, it could be hard to disentangle issues arising from new model behaviors or changes in the healthcare system.
To make things more concrete, here are some examples:
A model flags patients based on their risk of developing sepsis.
There is an increase in the population of patients admitted with respiratory complaints due to a viral pandemic.
This change in patient population leads to a massive increase in the number of patients the model flags, and the overall model performance drops because these patients do not end up experiencing sepsis.
It serves as an example of a static model being impacted by the changes in the healthcare system over time.
A model identifies physicians who could benefit from additional training.
The model uses a limited set of specially collected information.
Model developers create a new model version that utilizes EMR data.
After implementation, the updated model identifies physicians with better accuracy.
This improvement is an example of a static model being updated to improve performance over time.
Transition from Bench-to-Bedside
Implementation into clinical care requires the model to be connected to systems that can present it with real-time data.
We refer to these systems as infrastructure.
Infrastructure refers to the systems (primarily IT systems) needed to take data recorded during clinical care operations and present it in a format accessible to ML models.
This infrastructure determines the availability, format, and content of information.
Although data may be collected in the same source HIT system (e.g., an EMR system), the data may be passed through a different series of extract, transform, and load (ETL) processes (sometimes referred to as pipelines) depending on the data use target.
Once connected to clinical care, ML models need monitoring and updating.
For example, developers may want to incorporate knowledge about a new biomarker that changes how a disease is diagnosed and managed.
Model developers may thus consider updating models as a part of their regular maintenance.
Physician-AI Teams
This maintenance is complicated because models do not operate in a vacuum.
In many application areas, users interact with models and learn about their behavior over time.
In safety-critical applications, like healthcare, models and users may function as a team.
The user and model each individually assess patients.
The decision maker, usually the user, considers both assessments (their own and the model’s) and then makes a decision based on all available information.
The performance of this decision is the user-model team performance.
A Note on Deployment vs Integration vs Implementation
As we finish, I want to make a quick note on terminology.
We often use the terms implementation, deployment, and integration interchangeably; however, there are subtle but important distinctions between them.
I want to bring about a precision in language between these three terms.
Clearly defining them will help us discuss connecting AI tools to care processes more effectively.
Deployment—This one has a heavy-handed vibe; it may conjure up images of a military operation.
In the tech realm, it’s about pushing out code or updates from one side (developers) without much say from the other (users).
I view it as a one-way street, with the developers calling the shots.
However, this mindset doesn’t yield great results in healthcare, where the stakes are high, and workflow and subject matter expertise are paramount.
We can deploy code, but we should be wary of deploying workflows. Instead, we should co-develop workflows with all the necessary stakeholders.
Integration—This is the process of getting an AI model to work with the existing tech stack, like fitting a new piece into a complex puzzle.
But just because the piece fits doesn’t mean it will be used effectively or at all.
Integration focuses on the technical handshake between systems, but it can miss the bigger picture – workflow needs and human factors.
Implementation – This is where the magic happens.
It’s not just about the technical melding of AI into healthcare systems; it’s about weaving it into the fabric of clinical workflows and practices.
It’s a two-way street, a dialogue between developers and end-users (clinicians and sometimes patients).
Implementation is a collaborative evolving process that treats users as partners in the socio-technical development of an AI system.
It acknowledges that for AI to make a difference, it needs to be embraced and utilized by those on the front lines of patient care.
So, when discussing AI in healthcare, let’s lean more towards implementation.
It’s about more than just getting the tech right; it’s about fostering a collaborative ecosystem where we can make tools that genuinely contribute to better health outcomes by meeting the needs of clinical users and workflows.
Wrapping Up
We’ve traversed through technical integration, prospective validation, workflow integration, monitoring, and updating, each with its challenges and nuances.
We’ve also untangled some jargon—implementation, deployment, integration—words that might seem interchangeable but have different implications in healthcare AI.
Implementation is more than just a technical task; it’s a collaborative endeavor that requires developers and clinicians to collaborate, ensuring AI tools fit into healthcare workflows and genuinely enhance patient care.
This post wraps up our overview of the healthcare AI lifecycle.
To understand the technical infrastructure that powers these models, check out the post on Healthcare AI Infrastructure.
Herein lies an essential point for clarification with lay audiences. Most people unfamiliar with ML/AI have some expectation that models in use have a default dynamic updating behavior (i.e., that models are learning continuously over time). Dynamic updating hasn’t generally been the case with models deployed in healthcare. ↩
]]>Erkin ÖtleşHealthcare AI Development: From Data Access to Model Validation2024-09-02T00:00:00+00:002024-10-10T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-DevelopmentHealthcare AI Development
Welcome to the second post in our series on the healthcare AI lifecycle.
To start at the beginning, go to the overview post on the healthcare AI lifecycle.
Having established a general framework for the healthcare AI lifecycle, it’s time to cover some specifics.
Without a better starting point1, this post focuses on what I perceive to be the “beginning” of the AI lifecycle: the development phase.
Development encompasses the various processes involved in creating an AI model.
This phase is foundational, as the quality and success of the AI system largely depend on the quality of the development process.
Every step—from selecting the right task through training the model to validating its performance—is crucial to ensuring that the AI tool is effective and reliable in real-world clinical settings.
By the end of this post, you will have a comprehensive understanding of the critical steps in developing healthcare AI models and the challenges and considerations associated with each step.
Healthcare AI Development Portion of the Lifecycle.
The development phase encompasses all the steps necessary to create an AI model: task selection, data access, data preparation, model training, and culminating in model validation. This phase is crucial for building robust and effective AI tools that will be used in clinical care.
Development Steps
The development phase of healthcare AI is a multifaceted process that starts with a target task and ends with a (hopefully 🤞🏽) robust and effective AI model.
To provide a clear structure, I break down this phase into five discrete steps:
Task Selection
Data Access
Data Preparation
Model Training
Model Validation
As depicted in the figure above, it’s easiest to illustrate these steps as discrete and chronological.
However, this linear representation is disingenuous and doesn’t fully capture the reality of the development process.
These steps are semi-continuous and often non-linear.
Model developers frequently jump back and forth between these steps or work on them concurrently.
Despite this fluidity, these steps are generally present in all model development projects and tend to be finalized in the order presented.
This breakdown reflects my approach to structuring the development phase, providing a framework for understanding and navigating the complexities.
By understanding and addressing the nuances of these steps, we can ensure that the models developed are technically sound, clinically relevant, and reliable.
We will briefly discuss each development step, covering their key objectives and challenges.
Task Selection
Choosing the right problem for an AI model to tackle is crucial.
Selection involves identifying the specific task or clinical problem we aim to address with an AI model.
This step requires collaboration between clinicians and data scientists to ensure the model’s relevance and potential impact.
It’s not just about finding a novel problem; it’s about ensuring the AI solution can meaningfully improve outcomes or efficiency.
We’re looking for problems where AI can provide insights or automation that weren’t previously feasible.
Conducting thorough discussions with clinicians is essential to pinpoint where they feel the most pain or pressure and where they think AI could benefit them.
Their firsthand experience and insights are invaluable in identifying tasks that truly matter.
Clinician perspectives are important; however, caution should be exercised when someone says, “I just want an AI to predict/do X.”
There may be deeper or related problems that should be uncovered before jumping directly in the initial direction.
An excellent approach for overcoming this issue is to ask a series of probing questions.
Some of my favorite lines of inquiry are:
Sequential “Why?” Repeatedly asking “why?” (or “how?”) is often a fast way to understand the existing problem or system.
This iterative questioning can uncover underlying issues that might not be immediately apparent.
Would magic help? Asking how a “perfect solution” would help (e.g., “If I could give you Y information with 100% accuracy, how would that help?”).
Answering this question gives you a sense of the maximum possible benefit of a solution.
This helps us understand the potential impact and feasibility of the AI model.
Do you have data? If the answer is no, consider whether this project is feasible.
Data availability is a fundamental prerequisite for any AI development, and its absence can significantly hinder progress.
In addition to these considerations, it’s essential to be mindful of potential biases in task selection.
Suppose we choose a task such as predicting clinic no-shows (patients who do not attend a scheduled appointment).
In that case, we must recognize that this could be problematic due to inherent systemic biases.
Structural issues often prevent specific subpopulations from having consistent access to healthcare, and building a model for this task might inadvertently propagate these biases.
Instead of developing an AI model for predicting no-shows, it might be more beneficial to investigate other ways to address the root causes, such as creating programs to improve access to healthcare.
In this case, the best AI model may be no AI model at all, and it may be better to invest capital in building clinics closer to bus routes or developing more flexible clinic schedules.
By selecting the right task and thoroughly understanding the problem, we build a solid foundation for the subsequent steps in the AI development lifecycle.
This ensures that the AI model developed is technically sound, relevant, and impactful in real-world clinical settings.
Data Access
Getting the correct data is often the first big hurdle of AI development.
The data needs to be comprehensive, clean(able), and relevant.
This step frequently involves negotiating access to sensitive data, like medical records, while protecting patient privacy and data security.
You must consider the following:
Provenance: where is the data coming from? Who’s going to get it for you?
Protection: how will you ensure that the data are adequately protected? I recommend working directly in hospital IT systems or with hospital IT administrators/security specialists to specify compliant environments.
Prospective use: will you have this data available when using this system prospectively in the real world?
Model developers often default to readily available data, like the MIMIC dataset.
While MIMIC is great for research, it is probably not representative of your local hospital.
If you want to build a model for your local hospital, you’ll probably need access to its data.
Even after you get IRB approval, this can be an arduous process with many potential roadblocks.
For my projects, I’ve found it particularly helpful to be embedded in the health system (or to have partners who are) and to have the project goals aligned closely with the health system’s goals.
Additionally, knowing where the data are can make a huge difference.
I’ve found that occasionally, you have to guide data analysts to the data you need.
The best way to do this is to familiarize yourself with your health system’s EMR and data warehouses.
Data Preparation
Having obtained data, model developers may realize that healthcare data, like healthcare itself, is complicated.
Processing and transforming data for AI model development requires a unique mix of clinical and technical expertise.
Preparing this data for AI involves:
Cleaning it.
Dealing with missing values.
Transforming it into a format that algorithms can work with.
This step is usually labor-intensive; 90% of the engineering time will be dedicated to data preparation.
Tools can help automate data preparation.
I made a tool called TemporalTransformer that can help you quickly convert longitudinal EMR or claims data into a sequential token format ready for processing with neural networks or foundation models.
I discuss it in the supplement of my paper on predicting return to work.
Model Training
Training the model may be the most exciting step for the technical folks.
But it’s often one of the shortest parts of the project (in terms of wall time, not CPU/GPU time).
In this step, we select algorithms, tune parameters, and iteratively improve the model based on its performance.
This step is a mix of science, art, and a bit of luck.
The goal is to develop a model that’s both performant and generalizable.
There are many resources dedicated to model training and lots of nitty gritty to do into, I’ll save that all for another blog post.
Model Validation
After being developed, models must be validated to assess whether they benefit patients, physicians, or healthcare systems.
Validation means testing the model on new, unseen data to ensure it performs well in settings representative of intended real-world usage.
Ultimately, we must ensure the model doesn’t just memorize the data it’s seen but can also make good predictions when used in practice.
This step often involves internal and external validation to ensure robustness.
There are varying definitions for internal and external validation, but the distinction I like to use is based on the system generating the underlying data.
If the data comes from the same system (e.g., the same hospital, just a different time period), it is internal validation data.
A well-conducted external validation is a great way to assess whether a model will work in a new environment.
However, external validation may be challenging due to data-sharing restrictions.
Despite this challenge, it is often a great place to engage with healthcare AI systems, especially for physicians.
Here are some examples of external validation studies that I’ve worked on:
We’ve taken a closer look at the development phase of healthcare AI.
Each step is requires a blend of clinical insight and data science expertise.
While we’ve covered a lot of ground here, each development step could merit a more detailed post; please let me know if that’s something you would be interested in reading.
Also, if you have developed healthcare AI models, I’d love to know what challenges you have faced.
Once you’ve developed a model, the next step is integration into healthcare workflows.
Learn about that process in the post on Healthcare AI Implementation.
Thank you for joining me on this exploration of healthcare AI development.
“If you wish to make an apple pie from scratch, you must first invent the universe.” - Carl Sagan ↩
]]>Erkin ÖtleşAn Introduction to the Healthcare AI Lifecycle: From Development to Implementation2024-09-01T00:00:00+00:002024-09-22T00:00:00+00:00https://eotles.com/blog/Healthcare-AI-LifecycleThe Healthcare AI Lifecycle
Physicians frequently face life-or-death decisions in a bustling emergency department.
With medical knowledge expanding exponentially, how can they synthesize the latest evidence to provide optimal care?
Is there a way to bridge this gap between overwhelming data and timely, effective patient care?
The Challenge of Modern Healthcare
The practice of medicine is defined by complexity and a scarcity of time.
Physicians are expected to provide efficient, personalized, evidence-based care while navigating an ever-growing body of medical knowledge.
The traditional Evidence-Based Medicine (EBM) approach, which relies on data from clinical trials and observational studies to guide decisions, can be challenging to apply in real-time clinical settings.
EBM grounds diagnostic and therapeutic decision-making; however, it requires synthesizing multiple loosely connected pieces of scientific literature and assessing whether a patient’s presentation aligns with findings or criteria from previously published studies.
Consistently applying EBM decision-making in a busy clinical environment, especially one that caters to a wide range of patient conditions and acuity levels, like the emergency department, can be daunting.
Additionally, the current EBM process has a long lead time.
It can take years before data from a scientific study can be analyzed, assessed, disseminated, and integrated into clinical practice.
Enter artificial intelligence.
Although artificial intelligence has become a loaded term with many different meanings, my working definition is relatively simple:
Artificial Intelligence (AI) is intelligence, perceiving, synthesizing, or inferring information demonstrated by machines (non-human/non-living entities).1
We can use AI tools, also called models, to encode existing knowledge gathered from clinical trials or medical experts.
Additionally, many recent advances in AI have been driven by a set of techniques collectively known as machine learning.
Machine learning (ML) techniques seek to build models that learn or improve performance on a task given more data.2
ML offers powerful techniques to create data-driven prediction models that align well with the objectives of EBM.
ML methods can be used to rapidly develop models that learn the relationship between patient attributes (age, heart rate, etc.) and the patient’s future outcomes (e.g., risk of developing diabetes).
By leveraging AI and ML, we can significantly improve our ability to predict outcomes, personalize treatments, and ultimately enhance patient care.
ML models are already in clinical use, aiding the synthesis of complex medical information.
The Food and Drug Administration (FDA) has approved over 950 AI systems for various medical tasks, ranging from analyzing electrocardiograms to detecting breast cancer on mammograms.
Beyond these certified applications, health systems and health information technology (HIT) players, like electronic medical record (EMR) vendors, are developing and deploying AI systems that don’t require FDA certification.
These tools are designed to assist physicians by providing risk estimates.
The goal is to integrate these tools into medical decision-making processes and enhance the precision and effectiveness of patient care.
The landscape of healthcare AI systems is incredibly diverse.
AI tools can enhance or inform patient care, clinical decision-making, or operational efficiency.
Despite their variety, these systems fundamentally operate the same way as information processing tools.
So, whether used by patients, clinicians, or health systems, these tools share commonalities in their development and utilization.
Ensuring the safety and effectiveness of these systems requires a standard series of steps, collectively referred to as the healthcare AI lifecycle.
This lifecycle encompasses all the necessary phases to bring a healthcare AI system from conception to practical medical application.
Understanding the Healthcare AI Lifecycle
The healthcare AI lifecycle can be divided into two principal phases:
Development, when AI tools are created
Implementation, when AI tools are used in practice
It’s crucial to recognize that the journey of developing healthcare AI is continuous and doesn’t conclude once a model is deployed.
This ongoing commitment is vital to the success of AI in healthcare.
Like all other software development, healthcare AI requires refinement and iteration to adapt to new data, evolving medical knowledge, and changing clinical needs.
The distinction between development and implementation is somewhat artificial.
Effective AI integration into healthcare systems necessitates a blend of these phases, mirroring the principles of software engineering best practices.
Feedback loops between development and implementation ensure that AI tools remain relevant, accurate, and beneficial.
This iterative process, akin to agile methodologies in software engineering, is vital for maintaining the safety, efficacy, and utility of AI systems in a dynamic healthcare environment.
We can foster a more holistic approach by aligning AI development and implementation with established software engineering best practices.
This perspective encourages ongoing collaboration between developers and healthcare professionals, ensuring that AI tools evolve with medical advancements and real-world clinical experiences.
Bridging these phases can enhance the robustness and reliability of healthcare AI systems, ultimately leading to better patient outcomes and more efficient clinical workflows.
Healthcare AI Development & Implementation Lifecycle.
The development phase focuses on creating AI models, encompassing task selection, data access, data preparation, model training, and validation. The implementation phase involves integrating these models into clinical care, including technical integration, prospective validation, workflow integration, monitoring, and continuous updating. This lifecycle highlights the iterative and interconnected nature of AI development and implementation in healthcare, ensuring models remain effective and reliable in real-world clinical settings.
AI Development Overview
Development encompasses the multifaceted processes involved in creating an AI model; it can be broken down into several key steps:
Task Selection: Model development should begin with a process where experts identify the specific task or clinical problem an AI model should aim to address.
This step involves a collaborative effort between clinicians and data scientists, ensuring the model’s relevance and potential impact.
Your expertise is crucial in this process.
Data Access: Securing necessary datasets is often a significant hurdle.
Healthcare data is highly sensitive and complex, requiring careful handling and usually involving navigating regulatory and privacy constraints.
Data Preparation: Once data are obtained, they must be processed and transformed to be suitable for model development.
This step demands a unique blend of clinical and technical expertise to handle the intricacies of healthcare data, including cleaning, normalizing, and annotating the data.
Model Training: Once data are prepared, the actual development of an AI model can begin.
Training involves selecting appropriate algorithms, training the model, and fine-tuning it to optimize performance.
This step is iterative and often requires multiple adjustments to achieve desired performance characteristics (e.g., the targeted accuracy and reliability).
Validation: After training, the model must undergo rigorous evaluation, where we assess its performance in different ways.
There are several related ways to do evaluation; these include internal validation within the development environment and external validation, which tries to replicate other real-world settings.3
The goal is to ensure the model’s effectiveness and reliability in clinical practice.
External validation can be particularly challenging due to data-sharing restrictions, but it is essential for assessing the model’s real-world applicability.
Each of these steps is crucial in creating robust and reliable AI models.
We can craft tools that significantly enhance medical decision-making and patient outcomes by methodically addressing task selection, data access, data preparation, model training, and validation.
Many of these steps may be viewed as the purview of developers and engineers; however, physicians should be actively involved in every part of the journey.
Clinical expertise ensures that the AI tools are technically and clinically sound, yielding tools that are performant, practical, and aligned with patient care realities.
For a deeper dive into the development phase, check out the detailed post on Healthcare AI Development.
AI Implementation Overview
Implementation involves integrating and utilizing an AI model within clinical care settings.
Although the use of AI models in clinical care should only commence once a model has been thoroughly validated, some of these steps may begin in parallel to development.4
Additionally, implementation introduces many challenges that cannot be addressed during development.
The necessary steps of the implementation phase include:
Technical Integration: Implementing AI models requires connecting them to disparate HIT systems, including databases, web services, and EMR interfaces.
This technical work often involves complex interoperability issues and necessitates a deep understanding of AI models and HIT infrastructure.
Prospective Validation: The model needs to be validated in real-world settings after technical integration.
Prospective validation ensures the model performs well with real patient data and under actual clinical conditions.
Before full-scale deployment, it is essential to confirm model utility and reliability.
Workflow Integration: Ensuring that AI tools are seamlessly integrated into clinical workflows is crucial.
Workflow integration involves tailoring the AI model outputs into information that is easily interpretable and actionable by healthcare professionals.
The goal is to support clinical decision-making without adding unnecessary complexity or cognitive load.
Monitoring: Once deployed, AI systems require continuous monitoring to ensure they perform as expected.
Changes in patient populations, medical practices, and healthcare systems can degrade AI performance over time.
Continuous monitoring helps identify when a model’s predictions may no longer be reliable, prompting the need for an update or recalibration.
Updating: The dynamic nature of healthcare necessitates periodic updates to AI models.
Developers must engage with end-users to understand their needs and challenges, ensuring that the AI tools enhance rather than disrupt clinical practice.
This ongoing maintenance is vital for keeping AI tools accurate, relevant, and effective in delivering high-quality patient care.
In addition to these steps, successful implementation requires special attention to human factors and systems design.
AI models are not used in a vacuum; they must fit into healthcare providers’ existing workflows.
Developers must engage with end-users to understand their needs and challenges, ensuring that the AI tools enhance rather than disrupt clinical practice.
Despite their promise, successfully developing, implementing, and periodically updating AI models for healthcare is a challenging engineering task.
It requires a collaborative approach, with active involvement from technical experts and medical professionals.
Development teams can ensure that AI models enhance clinical care and patient outcomes by addressing the technical, human, and workflow considerations.
If you’re ready to explore the steps of implementing AI models in clinical workflows, visit the post on Healthcare AI Implementation.
The Importance of Collaboration
Successful AI integration in healthcare hinges on interdisciplinary collaboration:
Clinicians bring medical expertise and understand patient care nuances.
Engineers & Data Scientists contribute technical skills in AI and ML modeling.
IT Professionals ensure seamless technical integration and system maintenance.
Regulatory Experts navigate compliance with laws and guidelines.
Patients bring lived experience and should help set goals.
By working together, these stakeholders can develop AI tools that are technically sound, clinically relevant, and ethically responsible.
Ethical and Regulatory Considerations
Implementing AI in healthcare comes with significant ethical and regulatory responsibilities:
Patient Privacy: Adhering to regulations like HIPAA to protect sensitive health information.
Transparency: Ensuring AI models are interpretable and decisions can be explained.
Bias and Fairness: Mitigating biases in data that could lead to inequitable care.
Regulatory Compliance: Working with bodies like the FDA to meet approval requirements.
Addressing these considerations is crucial for building trust and ensuring patient safety.
Where Do We Go from Here?
Developing and implementing AI in healthcare is challenging and rewarding.
Approaching the steps outlined above with the proper technical and clinical perspectives is essential for harnessing AI’s full potential to improve patient outcomes.
This post is the first in a series that catalogs the elements of the AI lifecycle and the relevant infrastructure necessary to support it.
Be sure to explore the posts on AI development and implementation for a more in-depth look at these critical phases.
Additionally, we’ll dive into the HIT infrastructure that supports the creation and deployment of healthcare AI tools.
By the end of this series, you should have a comprehensive understanding of the healthcare AI lifecycle, the infrastructure required to support it, and the best practices needed to make these systems work effectively.
There’s some disagreement regarding the delineation between internal and external validation. Suffice it to say that it’s often contingent on where the data came from: here or there. ↩
This has been the traditional healthcare AI/ML development and implementation model. There is some evidence that this approach might need to be revised shortly. ↩
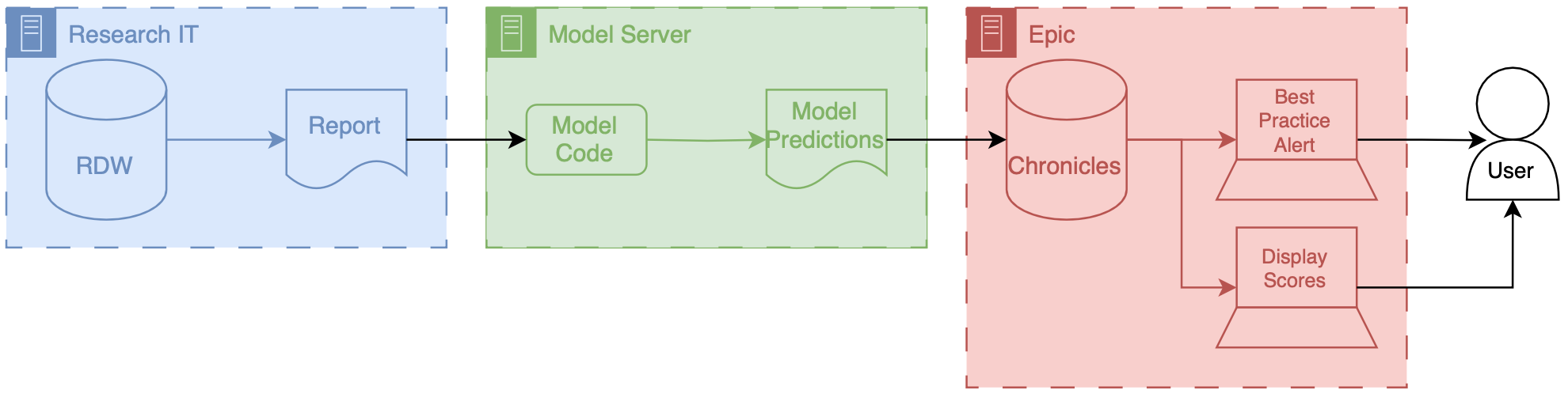
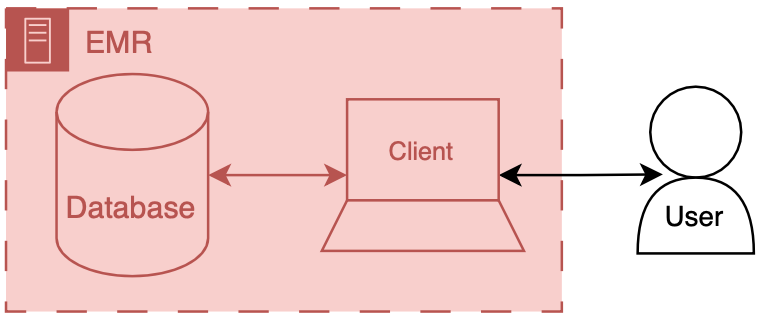
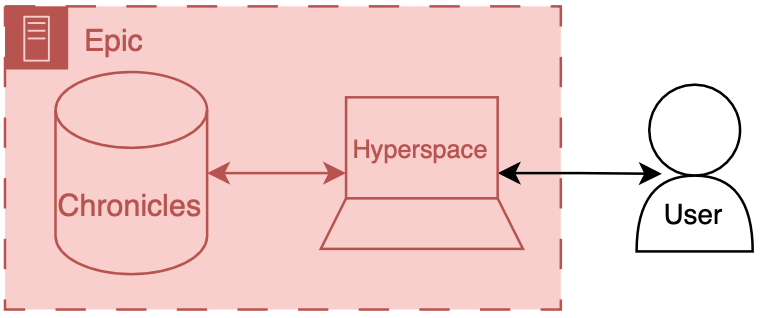
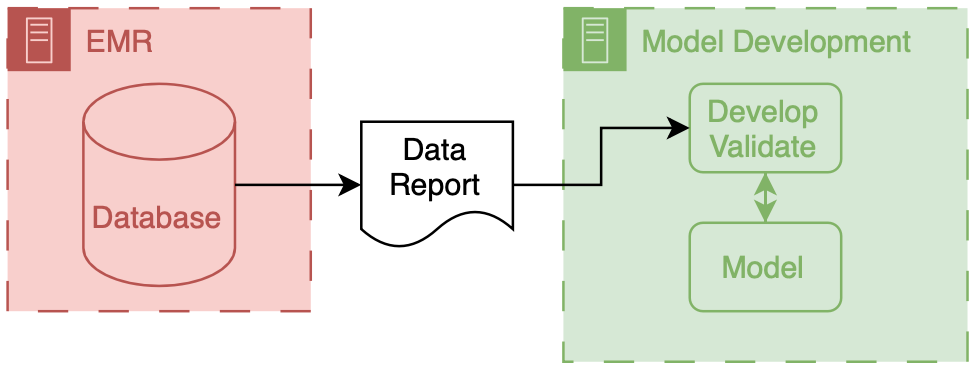
 .
Components owned by AI model developers are colored green
.
Components owned by AI model developers are colored green  .
Components represent shared research infrastructure that may be owned by the health system or research enterprise are blue
.
Components represent shared research infrastructure that may be owned by the health system or research enterprise are blue  .
Elements that don’t fit directly in one of these buckets are outlined in black
.
Elements that don’t fit directly in one of these buckets are outlined in black  .
.