
VO2 Max
VO2 Max is considered one of the best measurements of cardiovascular fitness and aerobic endurance. It represents the maximum oxygen consumption rate during exercise, expressed in milliliters (of oxygen) per kilogram of body weight per minute (ml/kg/min). The higher someone’s VO2 Max, the better their heart, lungs, and muscles can supply oxygen for energy production during sustained exercise. That’s why VO2 Max is often used as a benchmark for fitness and performance potential in endurance athletes. See the Wikipedia article on VO2 Max for more details.
However, directly measuring VO2 Max requires performing a maximal exercise test while breathing into a mask to analyze expired gases. This level of exertion is difficult for many people. That’s why researchers and companies have tried to develop ways to estimate VO2 Max levels using submaximal exercise data like heart rate.
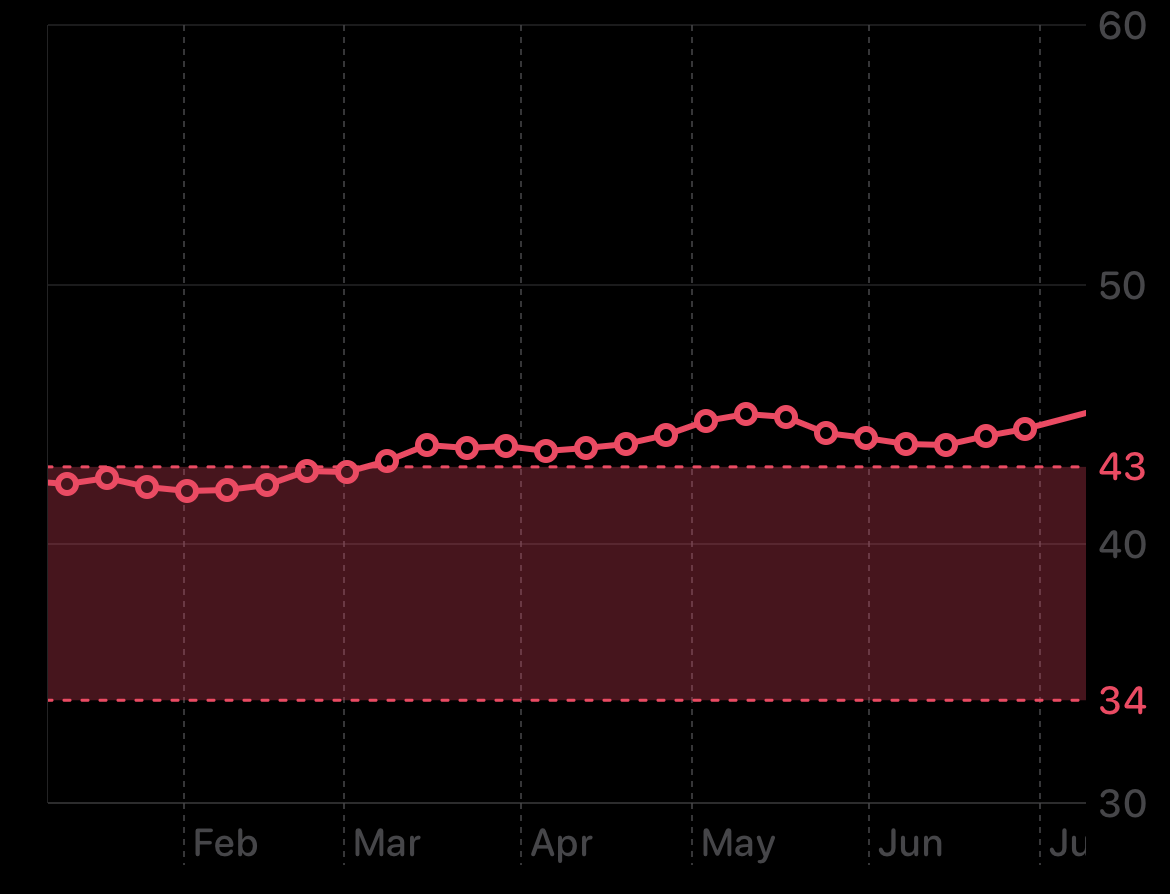
Apple has implemented its own VO2 Max estimation algorithm on the Apple Watch. After outdoor walking, running, or hiking workouts, the Watch will display a VO2 Max value based on the exercise data collected by the heart rate sensor and GPS. See Apple’s Heart Rate and VO2 Max support article. Apple doesn’t share the details of its estimation methodology, so I wanted to analyze my own HealthKit data to better understand how Apple calculates this metric.
Project Goals
The main goals for this analysis project are:
- Gain an understanding of what impacts Apple’s estimation of cardio fitness.
- Build capability to export, transform, and analyze Apple’s HealthKit data.
Secondary goals include:
- Identify which HealthKit data streams (heart rate, pace, etc.) are most correlated with estimated VO2 Max
- Use regression modeling and machine learning techniques to try to uncover insights into the algorithm behind Apple’s VO2 Max calculation
HealthKit Data Collection
To analyze the Apple Watch VO2 Max estimates, I first needed to collect my own HealthKit data from my iPhone. The Health app provides an export functionality that allows you to download your health data (Health app > User Profile (top right) > Export All Health Data). After a bit of processing, the Health app produces a zip file that can be exported from the app using Apple’s share sheet. At this point, I would note that you should use the “Save to Files” export option, as it was the only way I could get an export zip that wasn’t corrupt.
I extracted the zip once I got it onto my Mac. The extracted directory contains the data we will be using, export.xml, along with export_cda.xml, and two directories, electrocardiograms and workout-routes. export.xml contains the HealthKit data that we will be analyzing for this project.
HealthKit Data Extraction
I ran into a couple challenges working with the HealthKit export.xml file. For some reason, the XML is poorly formatted. To extract the data from the HealthKit XML export, I opted to use some python code shared by Jason Meno. This code parses through the XML file and converts it to a clean CSV format.
However, when I initially tried to run the code on my XML file, it ran into memory errors since it required the entire export.xml file to be loaded into memory. To resolve this, I made minor tweaks to the script so that it incrementally reads in the XML and writes out CSV rows without having the entire file contents in memory. My revised version of the code can be found here.
In the following posts, I’ll walk through my process of cleaning and analyzing the HealthKit data related to my outdoor workouts and VO2 Max estimates. I encountered some challenges wrangling the raw data that I’ll describe. Then, I plan on doing some data exploration and modeling. Let me know if you have any feedback on this introductory post or ideas for specific analyses to cover in subsequent posts!
UPDATE! The next post is up. Check it out if you want to learn more about how I extracted workout data.
Cheers,
Erkin
Go ÖN Home
PS
There are other tools to analyze and extract HealthKit data. Here’s a brief list of the alternatives I encountered while working on this project:
- Tutorial on Exporting and Parsing Apple Health Data with Python by Mark Koester
- Quantified Self Ledger GitHub
Acknowledgements
I want to thank Emily A. Balczewski for reviewing this post and providing feedback on it and the project!


