
Healthcare AI Development Infrastructure
This post is a part of the healthcare AI infrastructure series. Check out the intro post for a general lay of the land.
Implementation Should Inform Development
This post introduces several tools for developing healthcare AI models. Although AI models can be developed in isolation and implemented later, it’s more effective to approach development and implementation as interconnected processes. Projects are more successful when this connection is recognized, as most healthcare AI initiatives fail during implementation. These failures often stem from neglecting the constraints imposed by real-world applications. By understanding implementation challenges early on and designing with them in mind, you significantly increase the chances of success when it’s time to deploy the model.
While this post focuses on development, it’s written from the perspective of someone who has been through the entire process many times. I encourage you to read the upcoming post on implementation as well so you can fully understand the lifecycle before beginning your journey.
Overview
As mentioned in the last post, two key components are needed to build a model: data and a development environment (a computer). Data often comes from clinical databases, such as those in an EMR or other clinical systems. Once obtained, this data is transferred to computing environments designed specifically for model development, typically equipped with specialized software and hardware.
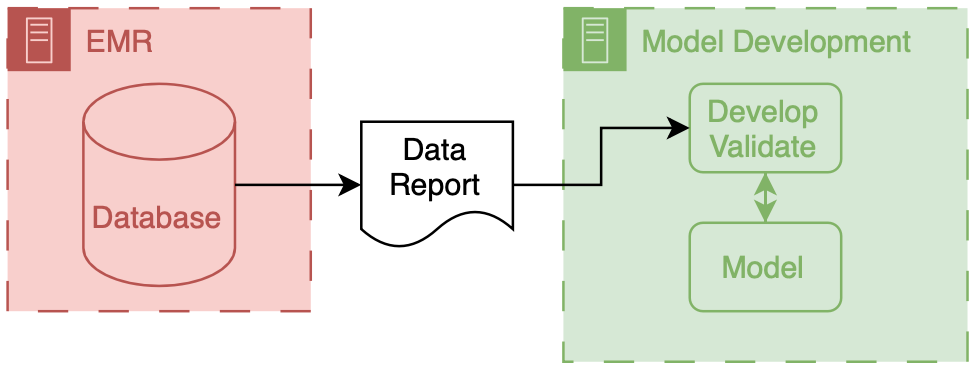
The above figure depicts the environments and data flows between them for model development. It’s straightforward, with data being extracted from the clinical system and then moved into a model development environment, where most development work is done.
Data
Data extracted from clinical systems can take many forms, with the most basic being a simple table where each row represents a patient and each column contains different types of information about them. Once you have research or quality improvement (QI) access, obtaining data from the EMR is relatively straightforward. When collaborating with your local Epic analysts (typically employed by the hospital), they will likely provide the data in Excel or CSV files. You can also access data from other sources, such as collaborative institutions (with shared IRB or BAA agreements) or open-source datasets like those available on PhysioNet.
Development Environments
Healthcare AI model development typically occurs on on-premises servers maintained by the health system or engineering departments that can ensure HIPAA compliance. Privacy is crucial—and deserves a dedicated post—suffice it to say that it’s essential to collaborate with your compliance and security teams to handle privacy correctly.
Regarding software, using a Linux or Windows operating system with a Python development environment is common. You’ll want to enable access to Python packages via a package/environment manager (like PyPi or Anaconda) since there’s a wealth of excellent open-source tools for this work (e.g., scikit-learn, PyTorch, TensorFlow). A powerful machine with plenty of RAM and CPU cores is essential; access to GPUs will significantly speed up your work.
Maintaining this infrastructure can be complex, which is why many are increasingly turning to cloud-based computing environments for these tasks1
Research Infrastructure
Now, we can discuss the specific infrastructure you may have to deal with. This infrastructure is often a shared resource supporting multiple types of data-driven research activities, such as health services research, epidemiology, and multi-omics.
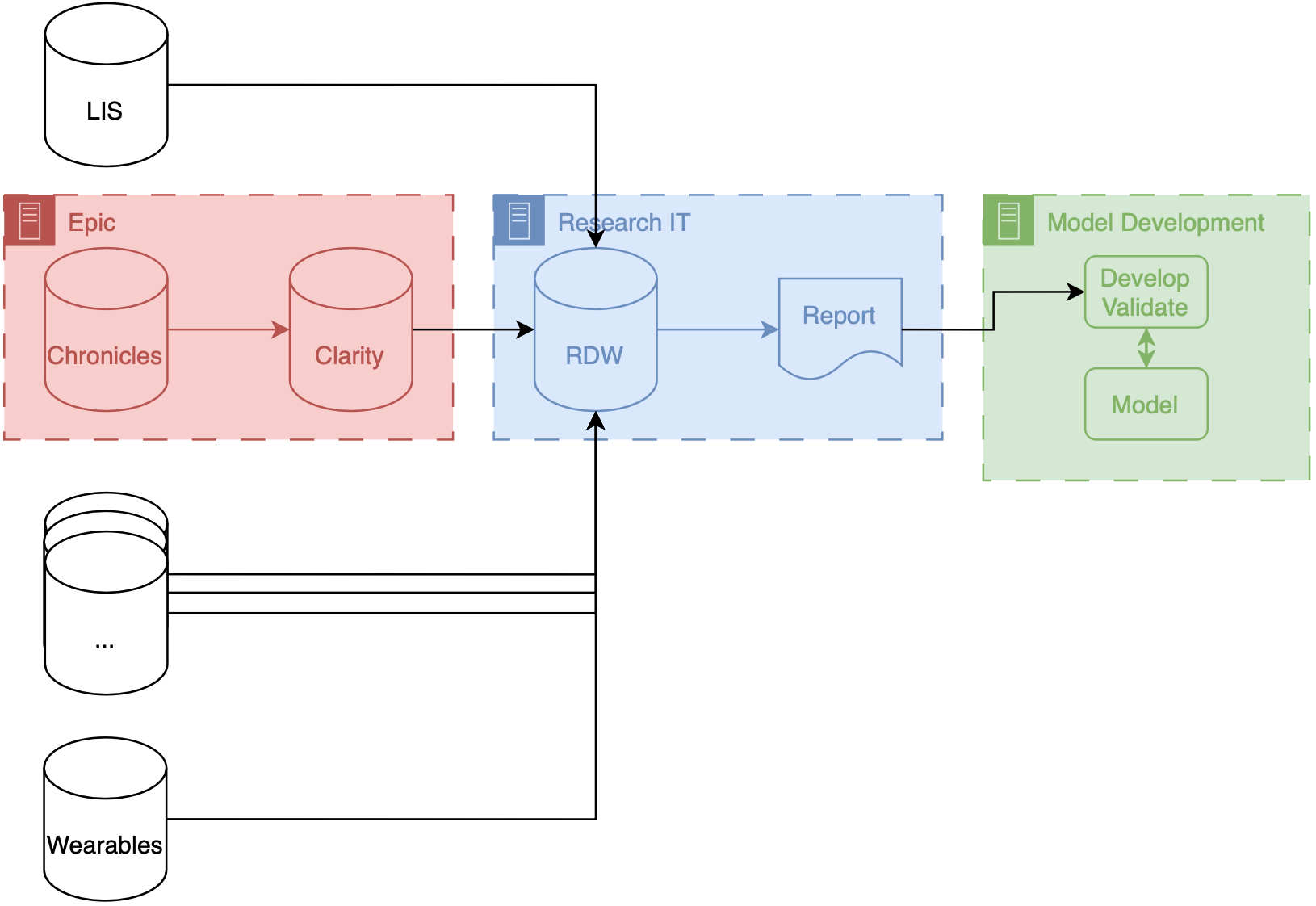
If your institution uses Epic, your research IT setup may be similar to what we have at Michigan (depicted above). Our data makes several stops before it gets to model developers. These stops are known as ETLs (short for extract, transform, load), processes that take data in a specific format and convert it to another format for entry into a database. There are two ETLs, the first of which is essentially mandatory.
Chronicles → Clarity
Chronicles is a database meant to support healthcare operations, which means it’s excellent at enabling the millions of transactions needed daily for patient care. But it’s not optimized for massive queries on large populations of patients. To offload and optimize these types of analytical queries, Epic created Clarity, a SQL database (built on top of SQL products like Microsoft SQL Server and Oracle Database) that is a transformation of the data stored in Chronicles. There is an ETL that runs every day that pulls data out of Chronicles and into Clarity.
Clarity → RDW
Researchers can access data directly from Clarity at some institutions, but that’s not the case at Michigan. Instead, a dedicated database for researchers, known as the research data warehouse (RDW), is used. RDW is an SQL database built on CareEvolution’s Orchestrate platform. This additional layer introduces some transformations but also enables the integration of other data types, such as wearable or insurer data, alongside EMR data.
Once data is queried from the RDW, it is transferred to the model development infrastructure, where engineers can work meticulously to build the model.
A note on ETLs
We have found that ETLs can impact the performance of AI models. There may be subtle differences between the data produced by an ETL process and the underlying real-time data. These differences are a form of dataset shift that we refer to as infrastructure shift. You can generally expect slightly reduced model performance when implementing models developed using data that have undergone ETL processes. For more information, check out our Mind the Performance Gap paper.
The Interface Between Development and Implementation
As we finalize models, we enter the interface between development and implementation. This transitional phase is tricky because it spans not only multiple steps in the lifecycle but also different types of infrastructure. I use the arbitrary distinction of technical integration as the dividing line: if the model is not yet receiving prospective data (i.e., it’s not technically integrated), it remains in development. From here on, much of the discussion depends on how the model developer implements the model. We will save most of this discussion for upcoming posts. However, we will quickly discuss the final stages of development necessary for projects that choose to implement using an EMR’s internal integration tooling.
Epic Development Infrastructure
If you decide to implement using Epic’s platform (or another vendor’s), you must ensure your model works on their infrastructure. AI-EMR internal integration is a complex area that will likely improve over time. However, to integrate technically within Epic, you’ll need to test and package your model using their custom development environment. I won’t dive into the details here, as your best resource is Epic Galaxy for the most up-to-date documentation.
As part of model development, Epic provides a Python environment equipped with standard AI/ML libraries (e.g., NumPy, Pandas, scikit-learn). They also offer custom Python libraries to facilitate interaction with their data interfaces.
- You can receive tabular data in a JSON format, which their libraries parse for you.
- After pre-processing the data, you can pass it to your model.
- Once your model generates predictions, you package them back to the EMR using another set of Epic’s Python functions.
Although the development environment is sandboxed, you are not overly constrained in the code you want to include. You can include additional Python and data files in the model package Additionally, you can call external APIs from within this environment if your organization safelists them. External API calls enable you to include information from other sources or to process data via another service.
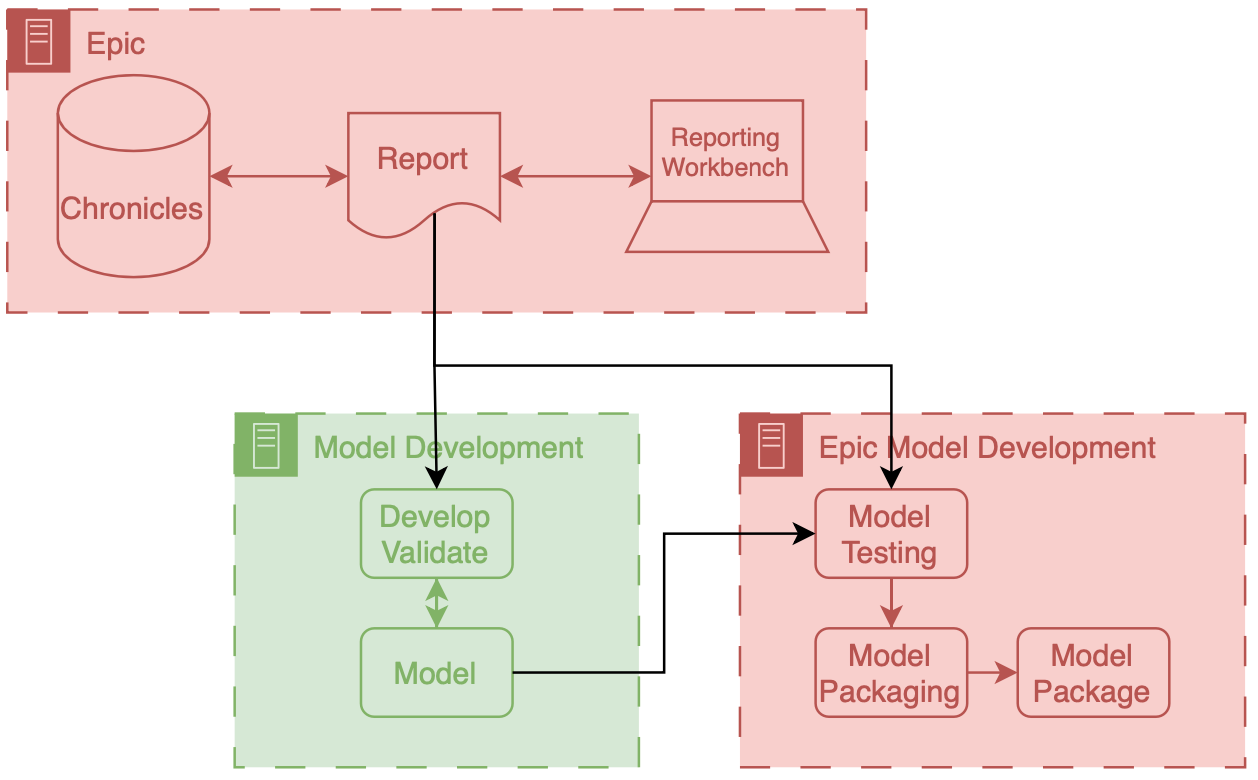
In this workflow, you take a model developed in your infrastructure and convert it into a package that can be run on Epic’s implementation infrastructure. A vital aspect of the workflow shown above is using a data report that comes directly from Chronicles (not Clarity) as part of this packaging process. This report is typically a small extract representing current patients in the health system. While small, it provides a highly accurate representation of prospective data since it is generated by the same infrastructure.
This small report creates a valuable opportunity to address infrastructure shift by using this real-time data alongside a more extensive, retrospectively collected research dataset during development. I think this approach could be worth exploring further—I might even consider researching this in the future.
Wrapping Up
In this post, we’ve covered the foundational aspects of healthcare AI model development, briefly touching on data acquisition and development environment setup. This brief discussion on the intersection of development and implementation highlights a key recurring theme: the importance of foresight and integrated planning in AI projects. By understanding how data is handled, transformed, and utilized throughout the process, developers can better anticipate the practical challenges that emerge during model implementation. This proactive approach streamlines the transition from development to deployment and improves the adaptability and effectiveness of the solutions we create.
In the next post, we will cover the infrastructure required to support AI implementation. Learn more in the AI Implementation Infrastructure post.
Cheers,
Erkin
Go ÖN Home
-
I’ve never done a cost breakdown analysis for on-premises vs. cloud for healthcare AI research, but I’d love to see results if anyone has some handy. ↩

