
NB: this series is still a work in progress.
Healthcare AI Infrastructure
This post started as a brief overview of healthcare AI infrastructure and then grew into an unwieldy saga incorporating my perspectives on building and implementing these tools. As such, I split the post into a couple parts. This part provides a general introduction, aiming to ground the discussion in the existing HIT landscape and setting up the general approaches for development and implementation.
This post is followed by detailed posts on development and implementation. In addition to providing more technical details these posts also walk through a couple projects that I’ve taken through the AI lifecycle. Discussing these projects will make the concepts a bit more concrete.
Basic Healthcare IT Infrastructure
Its important to ground our conversation in the basic healthcare information technology (HIT) infrastructure, primarily focusing on electronic medical records systems (EMRs). The reason for this is that the EMR is usually the source and destination of information processed by healthcare AI systems. Having a solid understanding of the parts of the EMR is the foundation to good healthcare AI infrastructure.
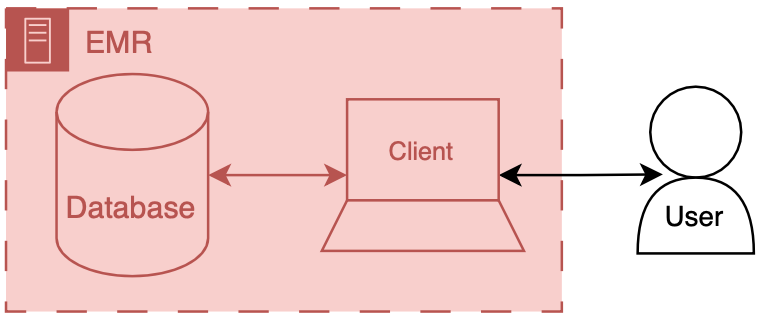
You can think of an EMR system as having two main components a database and client. The database’s primary job is to store the underlying data of the EMR - patient names, demographics, vitals, labs, all the good stuff. The client’s job is to present the user the information in a way that a human can understand. There’s a whole bunch of additional code, configuration, and data that we aren’t going to directly discuss, but we may obliquely refer to the amalgamation of that stuff along with our friends the database and client. The term front end refers to the client and all of its supporting code, configuration, and data handling mechanisms. Back end refers to the database and all of its supporting configuration and communication code along with any other code that drives the logic and behavior of the EMR.
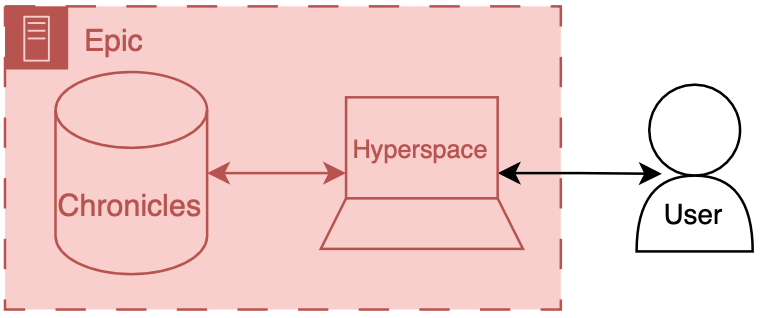
To make things more concrete I’ll briefly discuss the Epic specific names for these components.
Back end: Chronicles
Epic has a large back end written in a programming language called MUMPS (it is also known as M or Caché, which is a popular implementation of the language). MUMPS is a pretty interesting language for a variety of reasons (integrated key-value database, compact syntax, permissive scoping) - so I might write about it more in the future. The database management system that holds all of the operational real-time clinical data is called Chronicles, it is implemented using MUMPS for both the data storage and code controlling database logic, schema, indexing, etc.
Front end: Hyperspace
There are several distinct front ends for Epic; however there’s one that’s by far the most important - Hyperspace. Hyperspace is the big daddy interface that is found on all the computers in clinic and the hospital. It started out as Visual Basic application (I once heard a rumor that it was the largest piece of software ever made with VB); however, it is now mostly a .NET application. If you’re a doctor you may also interact with Epic’s other client software, like Haiku (client for mobile phone) and Canto (client for iPad). Hyperspace is the primary place that clinical work is done, notes are written, orders are placed, and lab values are reviewed here. These workflows are the primary places where additional contextual information would be helpful or where you would want to serve a best practice alert. Thus, since Hyperspace is the most likely end-target for most of our healthcare AI efforts.
There are a couple of ways to get information into Hyperspace. The first is to put stuff into the underlying database, Chronicles, and have the information integrated into the underlying mechanics of the EMR. The second is to have Hyperspace display a view of the information, but have it served from a different source (like your own web server). This is usually done through a iframe.1 These options are not limited to Epic EMRs, you should be able to take either approach with any type of modern EMR system.
Now that we have discussed the basic healthcare IT landscape we can start to talk about the specifics of making AI tools for healthcare.
AI Development Infrastructure
Now we can start to dig into the fun stuff - the actual building of healthcare AI models. At the most basic level you need two things to start building an AI model: data and development environment (a computer). Data often comes in the form of a report or extract from a database (often the EMR’s database). This data are then used to train a model using a computing environment that is set up for training models. These environments tend to be computers that are configured with special software and hardware that allow model developers to write code that can be used to develop and evaluate a model.
The data report out of underlying clinical systems can take a variety of forms. Their most basic embodiment is that of a simple table of data, where each patient is a row and columns represent different types of info about that patient. Once you have research or QI access it is pretty straightforward to get extracts of data from the EMR, when working with your local Epic analysts (employed by the hospital) they will probably give you data in the form of an excel or CSV file. You can also get data from other sources, like collaborative institutions (where you have a shared IRB or BAA) or open source datasets like those available on PhysioNet.
Healthcare AI model development has typically taken place on premises servers that were maintained by the health system or engineering departments capable of attaining HIPAA compliance. Privacy is super important - worthy of its own set of posts - but we won’t be able to it justice here - so make sure to work with your compliance people to do the right thing. In terms of software tts fairly standard to use a linux or windows operating system with a python development environment, you usually want to be able to allow python packages to be downloaded as there’s a lot of great open source software out there for this type of work (e.g., scikit-learn , pytorch, tensorflow). You’ll want to make sure that you have a fairly capable machine (lots of RAM and CPU cores), ideally having access to GPUs will make your life easier as well. Maintaining all this infrastructure can be pretty difficult, as such there’s been a growing consideration for using cloud-based computing environments.2
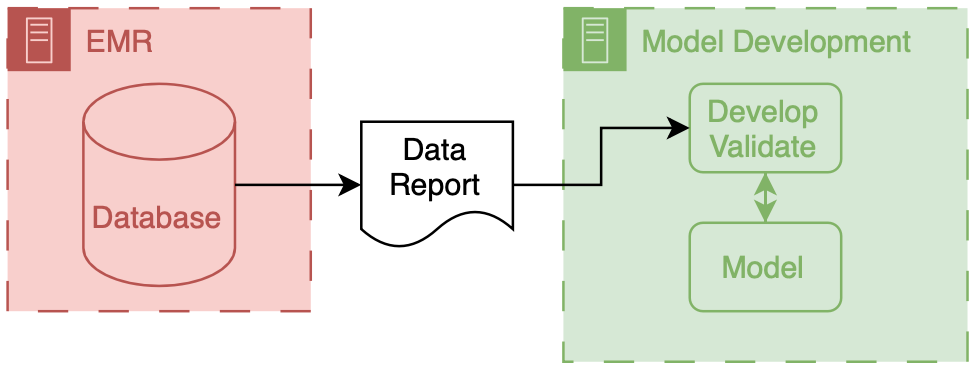
The above figure depicts the generic data flow for model development. Generally the data will flow linearly from a source clinical system towards our model development environment.
To help make the owners of the different components I have employed a consistent color scheme throughout this post.
Everything that is made and maintained by the EMR vendor (or their proxies) is red  .
Components owned by AI model developers are colored green
.
Components owned by AI model developers are colored green  .
Components represent shared research infrastructure that may be owned by the health system or research enterprise are blue
.
Components represent shared research infrastructure that may be owned by the health system or research enterprise are blue  .
Elements that don’t fit directly in one of these buckets are outlined in black
.
Elements that don’t fit directly in one of these buckets are outlined in black  .
.
Research Infrastructure
Now we can start to talk about the specific infrastructure that you may have to deal with. This infrastructure is often a shared resource that supports multiple different types of data driven research, like health services research, epidemiology, and multi-omics.
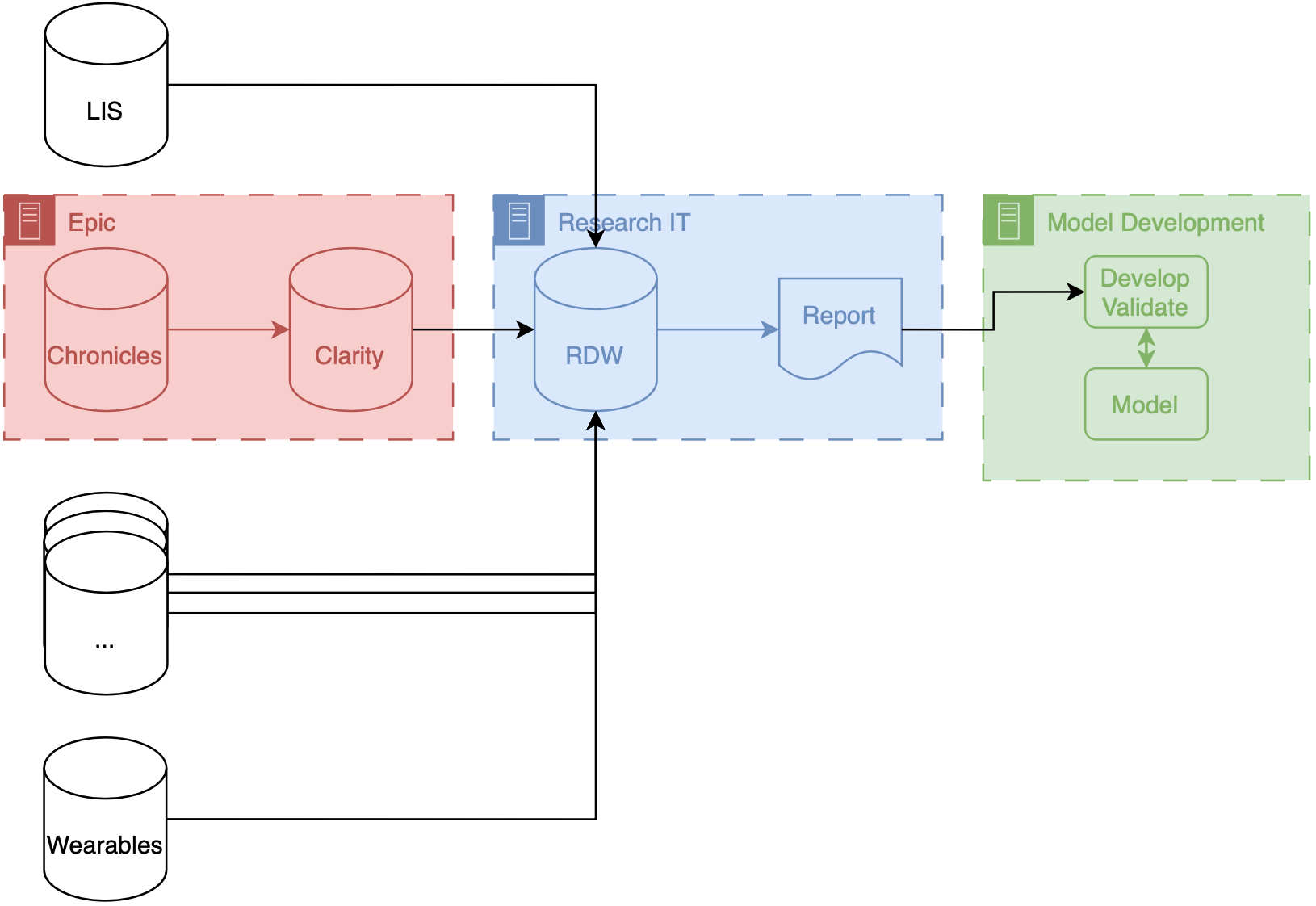
If your institution uses Epic your research IT set up may be similar to what we have at Michigan (depicted above). Our data makes several stops before it gets to model developers. These stops are known as ETLs (short for extract, transform, load), processes that take data in certain format and convert to another format for entry into a database. There are two ETLs, the first of which is pretty much mandatory.
Chronicles → Clarity
Chronicles is a database meant to support healthcare operations, but its not optimized for massive queries on large populations of patients. To offload and optimize these types of analytical queries Epic created Clarity a SQL database (its built using Microsoft SQL Server) that is a transformation of the data stored in Chronicles. There is an ETL that runs every day that pulls data out of Chronicles and into Clarity.
Clarity → RDW
Some institutions allow researchers to directly access data from Clarity. That’s not the case at Michigan, instead there is a database that is specifically designed for researchers, known as research data warehouse (RDW). RDW is also a SQL database and is built on top of CareEvolution’s Orchestrate tooling. This additional layer imposes some additional transformations but also allows other types of data, such as information from wearables or insurers, to be merged alongside the EMR data.
Data are then queried from RDW and then passed to the model development infrastructure. The engineers can then work diligently to produce a model.
A note on ETLs
We have found that ETLs may impact the performance of AI models. There may be subtle differences between the data that come out of an ETL process and the underlying real-time data. This is a type of dataset shift that we termed infrastructure shift and it means that you can expect slightly worse model performance in these situations. For more information check out our Mind the Performance Gap paper.
Transitioning from Development to Implementation
As we start to finalize models we end up at the interface between development and implementation. This interstitial space is tricky because it not only spans a couple steps of the lifecycle, but it also spans different types of infrastructure as well. I use the arbitrary distinction of technical integration as the demarcating line. If the model does not yet receive prospective data (not technically integrated) then its still in development. Much of the discussion from here on out hinges on how the model developer is choosing to implement the model. We will talk extensively about the choices and the implications in a little bit, but we’ve got to set up the last bit of development for one of these avenues.
Epic Development Infrastructure
If you choose to implementation using Epic’s tooling (or any other vendor’s) you will have to get your model to work on their infrastructure. This is a wonky space that will likely get better over time. But in order to do technical integration with Epic you need to test and package your model using a custom development environment that they provide. I won’t go into a ton of details here, as you’re best served by going to Epic Galaxy to see the latest and greatest documentation.
As a part of model development Epic provides a Python environment with a load of standard Python AI/ML libraries (…list) They also provide a couple custom Python libraries that help you interact with the data interfaces.
- You can receive tabular data in a JSON structure that is parsed by their libraries You can then pre-process the data and pass it to your model
- Once you have your predictions you packaged up the data using another set of Epic’s Python calls.
Although the development environment is sandboxed, you are not overly constrained in terms of the code you want to include. You can include additional python and data files in the model package Additionally you can call external APIs from within this environment if they are whitelisted. This means that you could include information from other sources or do data processing via another service.
You can take an existing model that was developed in and as long as you use epic approved list of libraries, you can use epic bundling tools to then convert it into a package that can be run on their ECP instance the way that the model receives, data is through a reporting workmen report so you’ll work with your epic analyst to set up a report essentially is the tabular data you want your models received so you specify all the columns and have this done you’ll also have an epic analyst.
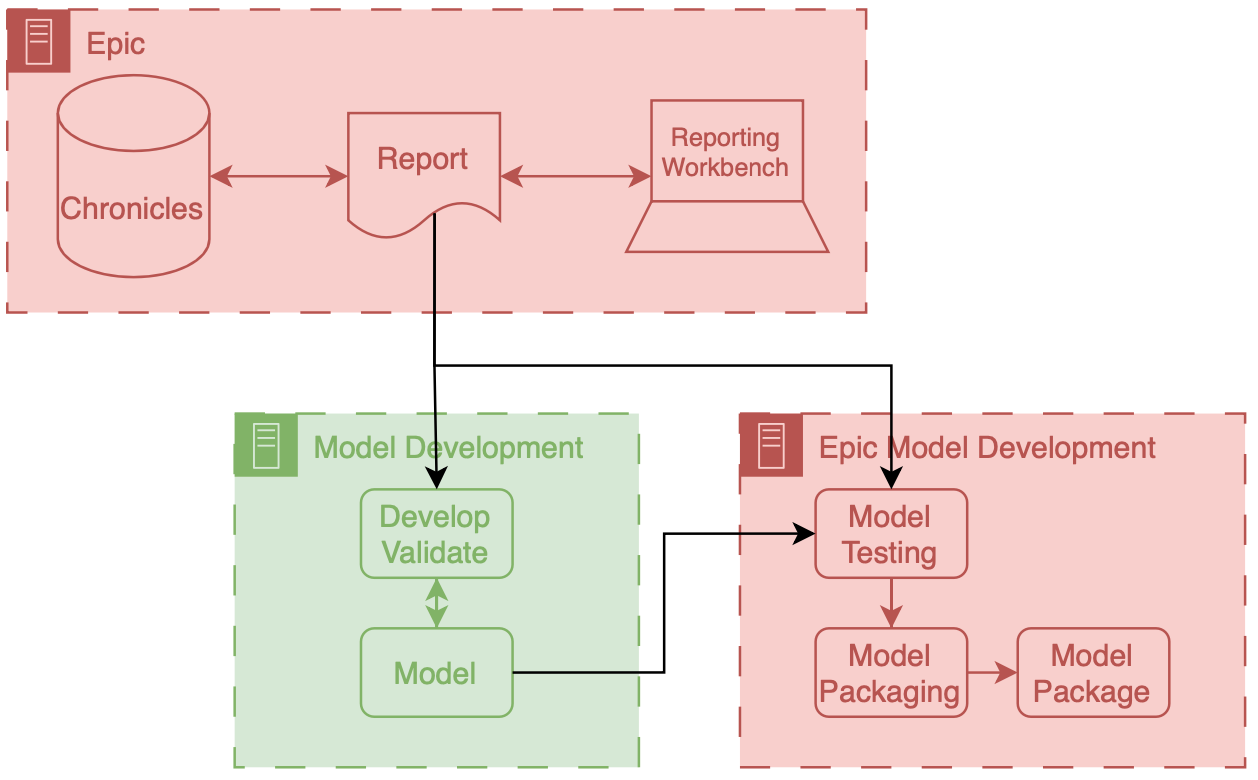
In this workflow you assess and convert a model that you made with your own infrastructure into a package that can be run on Epic’s implementation infrastructure. What’s crucial about the workflow depicted above is that there’s a data report that comes directly out of Chronicles (not Clarity) that you use as a part of this packaging workflow. This is report is often a small extract representing current patients in the health system. Thus, despite being small it is a very good representation of what the data will look like prospectively, as its generated by the prospective infrastructure. I think its a really good opportunity to address infrastructure shift, if the model developer uses this data in additional to a larger retrospectively collected research dataset for development. Maybe I’ll do some research in this direction…
AI Implementation Infrastructure
Now we turn our attention to connecting models into care processes, implementation. As discussed in the previous post, implementation goes beyond the technology, however, the primary focus of this section will be on the implementation step of technical integration, the nuts-and-bolts of connecting AI models to existing HIT systems.
Overview
There are two primary ways to integrate a model into existing HIT systems and they are delineated by the relationship to the EMR: internal and external.
Internal integration of models means that developers rely exclusively on the tooling provided by the EMR vendor to do the hosting of the model along with all of the logic around running it and filling the results.
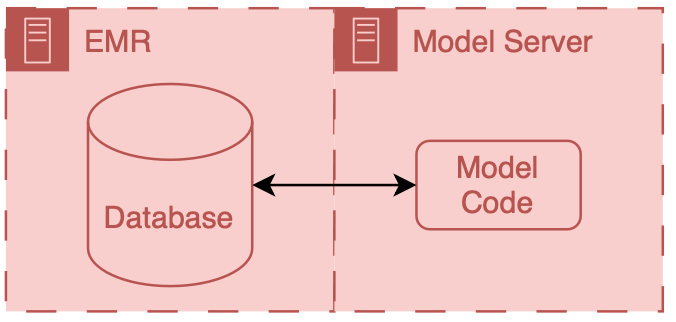
External integration of models means that developers choose to own some of parts of the hosting, running, or filing (usually its the hosting piece).
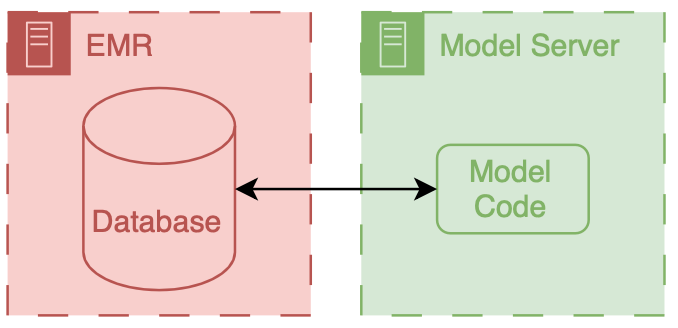
In both scenarios data ends up flowing from the EMR database to the model, however the path that these data take can be drastically different and significant thought should be put into security of the data and the match between the infrastructure and model’s capabilities.
It is important to note that these approaches delegate the display of model results to the EMR system. They do this by passing model results to the EMR and using EMR tools to display the results to users.
Internal Integration
The infrastructure choices of internal integration are fairly straightforward, as its all dictated by the EMR vendor so you may not have many options. In the past this would have meant re-programming your model so that it could be called by code in the EMR (e.g., for Epic you would need to have it be a custom MUMPS routine). Luckily now EMR vendors are building out tools that enable (relatively) easy integration of models.
Limitations
However, there are some major restrictions, because these are not servers that are totally under your control. Instead they are platforms that are designed to be safe and effective for a variety of use cases. Thus, they tend to have a couple attributes that may be problematic.
The first is sandboxing, the model code runs in a special environment that has a pre-specified library of code available. As long as you only use code from that library your model code should function fine, however if you have an additional dependence outside that library you may run into significant issues.
The second is conforming to existing software architectures. Expanding enterprise software often means grafting existing components together in order to create new functionality. For example, existing reporting functionality may be used as the starting point for an AI hosting application. While this makes sense (reporting gets you the input data for your model), it means that you maybe stuck with a framework that wasn’t explicitly designed for AI.
The sandboxing and working with existing design patterns means that square pegs (AI models) may need to be hammered into round holes (vendor infrastructure). Together this means that you seed a significant amount of control and flexibility. While this could be viewed as procrustean, it may actually be a good thing as it does force AI models to adhere to certain standards and ensures that there’s a uniform data security floor.
Example
Generally, for this setup you have to a model package and some additional configuration. The model package contains your model and the code necessary to package your model in a manner that can be run on the hosting service and that you have additional configuration that determines the data passed to the model
We set up our MCURES project using an internal integration approach. MCURES was an in-hospital deterioration index tailored for patients admitted to the hospital for acute respiratory failure during the COVID-19 pandemic. Since we were trying to get this model developed and implemented as fast a possible I chose to go down the internal integration pathway. Additionally, we started doing the technical integration work in parallel to model development.
At the time we started the MCURES project Epic they offered two options for internal integration:
- Epic Cognitive Computing Platform (ECCP) and
- Predictive Model Markup Language (PMML).
Epic’s PMML approach is interesting because you essentially specify the model via configuration (using the PMML standard) and Epic builds a copy of the model based on their implementations of different model architectures. I have not built anything using this approach; however, based on my research at the time it seemed fairly limited, as it supported a small handful of simple model architectures.
Because of the model architecture limitations of PMML we decided to go with ECCP for MCURES. ECCP enables you to run models in you’ve developed in Python using a proprietary model serving infrastructure. This model serving infrastructure is essentially a sandboxed Python AI environment hosted using Microsoft Azure. At a high level data are passed from Chronicles to this special Azure instance, the model produces predictions, which are then passed back to Chronicles. ECCP takes care of the data transitions and AI developers primarily need to worry about their AI code.
Model input data is passed out of chronicles using reporting workbench. Reporting workbench is designed for different types of EMR reports. You can configure special versions of these reports that would pull the necessary data for patients that could be used for an AI model. Data are in a tabular structure, where rows represent patients or encounters, and columns represent attributes like age, current heart rate, etc.. I won’t go into a ton of details here, but this is the place where you can run into significant limitations, because the underlying data in Chronicles isn’t actually tabular, and the best representation of longitudinal health data is often also not tabular as well so there’s lots of engineering that needs to be done in order to get a good representation of the patients.
Data will then be passed and secure manner to the model, which is running on the special Azure instance. We talked a little bit about model packaging so we won’t go into that here. But there is some configuration that is needed when running the model in real time, in addition to the model we need a couple items:
- input data report, and
- model run information.
We need to explicitly connect the reporting workbench model discussed above to our configuration. Additionally, we need to instantiate the logic that controls the frequency at which the model runs. For this one creates a special Epic batch job that will run with a specified frequency. This job runs the reporting workbench reports and passes that data to the model process that then calculated predictions.
The predictions computed by the model are then passed back to Chronicles. These end up in special in a special part of the database that’s designed to store predictive model results The kind of information that you can pass back are a little bit limited because the database is expecting certain types of information.
When the data is back in Chronicles you serve it to users in many different ways. For example, you could use it to fire best practice alerts or have it be highlighted as an additional column in a list of patients stratify patients based on a risk score. This is all fairly easy to do because you’ve already been working with your epic analysts to get the data directly into the status structure, and then they can work with their colleagues to set up the best practice alert, or column display.
Despite a couple technical limitations, the entire flow data from Chronicles to ECP and back to Chronicles controlled, unless you have pretty good guarantees about Safety and reliability.
One thing major limitation of this integration approach is that a significant amount of the model run configuration is controlled by health system analysts as opposed to model developers. This is fine if there is really good communication between the two parties, but there’s often a big disconnect, because analysts sort of sit in a siloed place inside of health system IT And developers tend to be outside of direct health IT and structure. Usually this ends up devolving into a big game of telephone, as these parties that don’t normally talk to one another or have good relationships. So, as always, we need to work on this so part of our sociotechnical system.
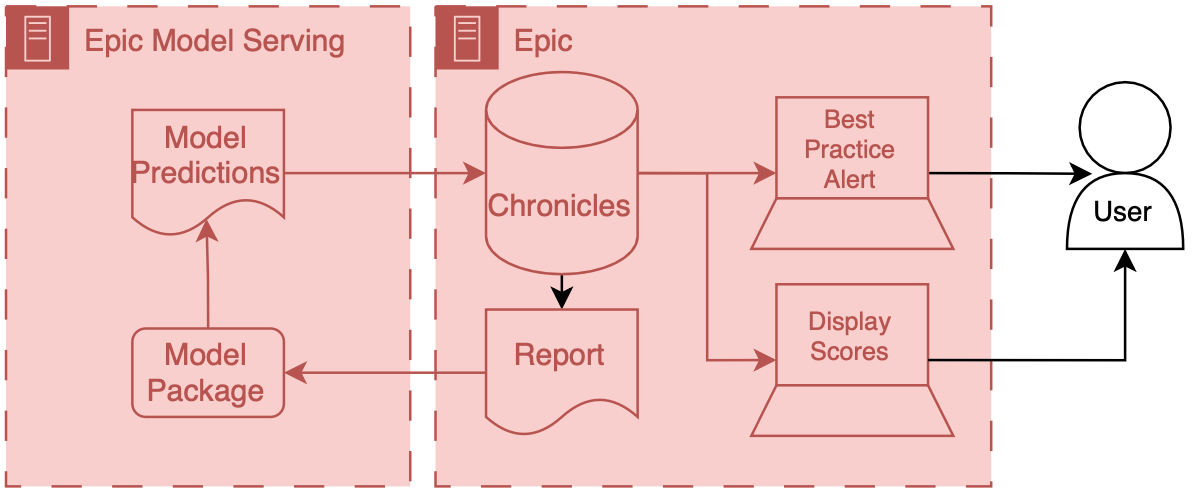
This decision to do technical integration simultaneously with model development turned out to be fairly important. The learnings from technical integration directly impacted our choices for model development. For example, we realized that building the reporting workbench report was a relatively laborious process. Each column in the report took a good amount of time to build and validate. These columns corresponded to a variable (also known as a feature) that the model took as input. So the integration effort scaled linearly with the number of features we wanted to include in the model.
During early parts of development we were exploring models with thousands of features, as we had access to the features from RDW and had code to easily manage these features. However, once we learned more about integration effort we decided to cap the number of features being used to a fairly small number (around 10). We felt comfortable with this decision because we felt like we hit a good balance between performance and implementation time. Our early experiments indicated that we wouldn’t lose a ton of performance going from thousands of features to ten (something on the order of less than 10% relative decrease in AUROC) and we were fairly sure that we could implement and test the report with the allocated Epic analyst built time.
External Integration
External integration is the other side of the coin. Model developers can pick out exactly how they want their model to be hosted and run as well as how they would like it to interface with the EMR. This additional flexibility is great if you are working on cutting edge research, but it carries a significant burden in terms of guaranteeing that data are handled in a safe and secure manner.
External integration offers a path where innovation can meet clinical applications, allowing for a bespoke approach to deploying AI models. This flexibility, however, comes with its own set of challenges and responsibilities, particularly in the realms of security, interoperability, and sustainability of the AI solutions.
Limitations
Below are key considerations and strategies for effective external integration of AI in healthcare:
- Security and Compliance When hosting AI models externally, ensuring the security of patient data and compliance with healthcare regulations such as HIPAA in the United States is paramount. It is essential to employ robust encryption methods for data in transit and at rest, implement strict access controls, and regularly conduct security audits and vulnerability assessments. Utilizing cloud services that are compliant with healthcare standards can mitigate some of these concerns, but it requires diligent vendor assessment and continuous monitoring.
- Interoperability and Data Standards The AI model must interact with the EMR system to receive input data and return predictions. Adopting interoperability standards such as HL7 FHIR can facilitate this communication, enabling the AI system to parse and understand data from diverse EMR systems and ensuring that the AI-generated outputs are usable within the clinical workflow. An alternative is to use a data integration service, like Redox.
- Scalability and Performance External AI solutions must be designed to scale efficiently with usage demands of a healthcare organization. This includes considerations (that some may consider boring) for load balancing, high availability, and the ability to update the AI models without disrupting the clinical workflow. Performance metrics such as response time and accuracy under load should be continuously monitored to ensure that the AI integration does not negatively impact clinical operations.
- Support and Maintenance External AI solutions require a commitment to ongoing maintenance and support to address any issues, update models based on new data or clinical guidelines, and adapt to changes in the IT infrastructure. Establishing clear service level agreements (SLAs) with vendors or internal teams responsible for the AI solution is crucial to ensure timely support and updates.
Example
I’ll detail the external integration of one of our models. This is the model that we developed to integrated for C. difficile infection risk stratification.
Data for this model comes from our research data warehouse then travels to the model posted on a Windows virtual machine. The predictions from the model are then passed back to the EMR using web services.
We have a report that runs daily from the research state warehouse. It’s a stored SQL procedure that runs at a set time very early in the morning about 5 AM. This is essentially a large table of data for each of the patients that were interested in producing a prediction on rows our patients and columns are the various features that were interested in. Stored procedures update information in a view inside of RDW.
The research data at warehouse and this view are accessible by a Windows machine that we have inside of the health IT secure computing environment. This windows machine has a scheduled job that runs every morning about at about 6 AM. This job pull the data down from the database runs a series of python files that you data pre-processing and apply the model to the data to the transform data, and then save the output, model predictions to a shared secured directory on the internal health system network.
We then returned the predictions to Chronicles, using infrastructure that our health IT colleagues helped to develop. This infrastructure involves a scheduled job written in C# that reads the file that we have saved the shared directory does date of validation and then passes data into chronicles using epics web services framework.
These data end up as flow sheet values for each patient. We then worked with our epic analyst colleagues to use the flow sheet data to trigger as practice alerts, and also to populate port. The best practice alerts fire based off of some configuration that’s done inside of epic in order to be able to adjust the alerting threshold outside of Epic what we did was we modified the score such that the alerting information with someone distinct from the actual score so what we did is we packed an alert flag and the score together into a single decimal separated value and this is essentially a number however it’s unique and that it contains two pieces of information so we could take a patient to Oehlert on and we would say 1.56 a patient that we didn’t alert on would be zero point
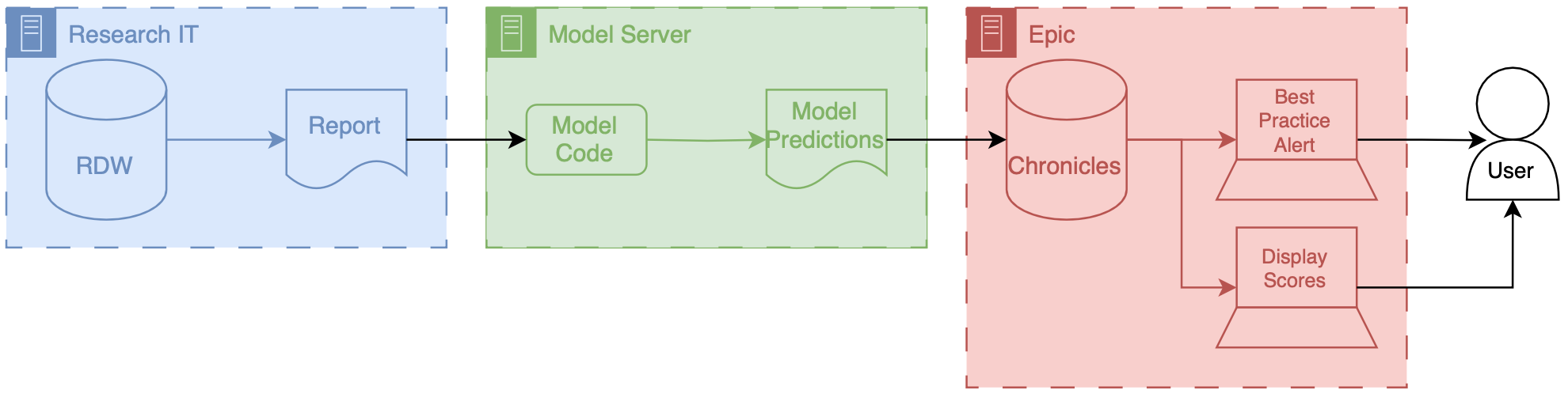
Model predictions are passed to the EMR system using web services. Predictions are then filed as either flowsheet rows (inpatient encounters) or smart data elements (outpatient encounters). You have to build your own infrastructure to push the predictions to the EMR environment.
Bonus: Another Approach to External “Integration”
A great deal of the effort involved in external integration is assuring that the data travels between the EMR and your hosted AI model in a safe and secure manner. Setting up all the plumbing between the EMR and your system can take the vast majority of your development time.
Let’s say you didn’t want to go through the hassle, but still wanted to enable clinical users to interact with your model. Well you could provide them with a (secure) way to access your model online and have them be the information intermediaries.
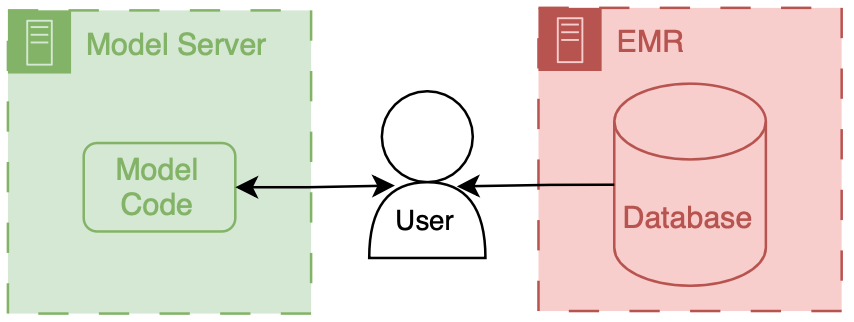
This is exactly what MDCalc does. They have lots of models that physicians can go and input data directly into. They are super useful clinically, but they’re not integrated into the EMR.
If the amount of data that your model uses is small (a handful of simple data elements), then this could be a viable approach. And if you don’t collect PHI/PII then you could set up your own MDCalc like interface to your hosted model.
We won’t talk about this architecture in depth, but I think its a potentially interesting way to make tools directly for clinicians.
Cheers,
Erkin
Go ÖN Home
-
This can be complicated to do because you need to maintain you own application server and also deal with passing authentication between the EMR session and your application. ↩
-
I’ve never done a cost break-down analysis for on-premises vs. cloud for healthcare AI research, but I’d love to see results if anyone has some handy. ↩


