
Healthcare AI Development
Welcome to the second post in our series on the healthcare AI lifecycle. To start at the beginning, go to the overview post on the healthcare AI lifecycle. Having established a general framework for the healthcare AI lifecycle, it’s time to cover some specifics. Without a better starting point1, this post focuses on what I perceive to be the “beginning” of the AI lifecycle: the development phase.
Development encompasses the various processes involved in creating an AI model. This phase is foundational, as the quality and success of the AI system largely depend on the quality of the development process. Every step—from selecting the right task through training the model to validating its performance—is crucial to ensuring that the AI tool is effective and reliable in real-world clinical settings.
By the end of this post, you will have a comprehensive understanding of the critical steps in developing healthcare AI models and the challenges and considerations associated with each step.
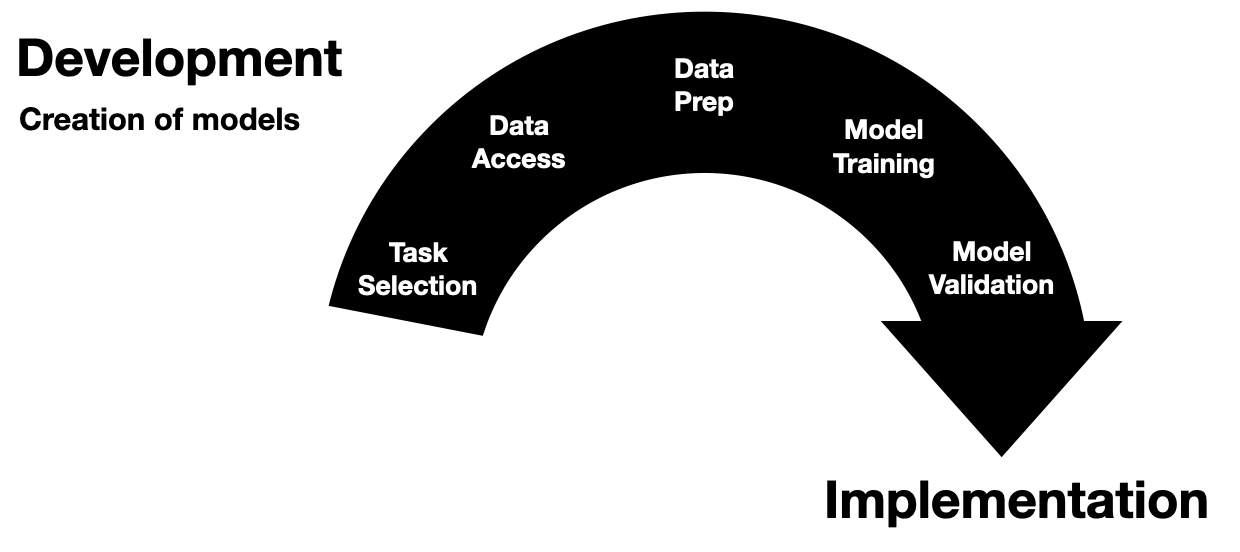
Development Steps
The development phase of healthcare AI is a multifaceted process that starts with a target task and ends with a (hopefully 🤞🏽) robust and effective AI model. To provide a clear structure, I break down this phase into five discrete steps:
- Task Selection
- Data Access
- Data Preparation
- Model Training
- Model Validation
As depicted in the figure above, it’s easiest to illustrate these steps as discrete and chronological. However, this linear representation is disingenuous and doesn’t fully capture the reality of the development process. These steps are semi-continuous and often non-linear. Model developers frequently jump back and forth between these steps or work on them concurrently. Despite this fluidity, these steps are generally present in all model development projects and tend to be finalized in the order presented.
This breakdown reflects my approach to structuring the development phase, providing a framework for understanding and navigating the complexities. By understanding and addressing the nuances of these steps, we can ensure that the models developed are technically sound, clinically relevant, and reliable.
We will briefly discuss each development step, covering their key objectives and challenges.
Task Selection
Choosing the right problem for an AI model to tackle is crucial. Selection involves identifying the specific task or clinical problem we aim to address with an AI model. This step requires collaboration between clinicians and data scientists to ensure the model’s relevance and potential impact. It’s not just about finding a novel problem; it’s about ensuring the AI solution can meaningfully improve outcomes or efficiency. We’re looking for problems where AI can provide insights or automation that weren’t previously feasible.
Conducting thorough discussions with clinicians is essential to pinpoint where they feel the most pain or pressure and where they think AI could benefit them. Their firsthand experience and insights are invaluable in identifying tasks that truly matter.
Clinician perspectives are important; however, caution should be exercised when someone says, “I just want an AI to predict/do X.” There may be deeper or related problems that should be uncovered before jumping directly in the initial direction. An excellent approach for overcoming this issue is to ask a series of probing questions. Some of my favorite lines of inquiry are:
- Sequential “Why?” Repeatedly asking “why?” (or “how?”) is often a fast way to understand the existing problem or system. This iterative questioning can uncover underlying issues that might not be immediately apparent.
- Would magic help? Asking how a “perfect solution” would help (e.g., “If I could give you Y information with 100% accuracy, how would that help?”). Answering this question gives you a sense of the maximum possible benefit of a solution. This helps us understand the potential impact and feasibility of the AI model.
- Do you have data? If the answer is no, consider whether this project is feasible. Data availability is a fundamental prerequisite for any AI development, and its absence can significantly hinder progress.
In addition to these considerations, it’s essential to be mindful of potential biases in task selection. Suppose we choose a task such as predicting clinic no-shows (patients who do not attend a scheduled appointment). In that case, we must recognize that this could be problematic due to inherent systemic biases. Structural issues often prevent specific subpopulations from having consistent access to healthcare, and building a model for this task might inadvertently propagate these biases. Instead of developing an AI model for predicting no-shows, it might be more beneficial to investigate other ways to address the root causes, such as creating programs to improve access to healthcare. In this case, the best AI model may be no AI model at all, and it may be better to invest capital in building clinics closer to bus routes or developing more flexible clinic schedules.
By selecting the right task and thoroughly understanding the problem, we build a solid foundation for the subsequent steps in the AI development lifecycle. This ensures that the AI model developed is technically sound, relevant, and impactful in real-world clinical settings.
Data Access
Getting the correct data is often the first big hurdle of AI development. The data needs to be comprehensive, clean(able), and relevant. This step frequently involves negotiating access to sensitive data, like medical records, while protecting patient privacy and data security. You must consider the following:
- Provenance: where is the data coming from? Who’s going to get it for you?
- Protection: how will you ensure that the data are adequately protected? I recommend working directly in hospital IT systems or with hospital IT administrators/security specialists to specify compliant environments.
- Prospective use: will you have this data available when using this system prospectively in the real world?
Model developers often default to readily available data, like the MIMIC dataset. While MIMIC is great for research, it is probably not representative of your local hospital. If you want to build a model for your local hospital, you’ll probably need access to its data. Even after you get IRB approval, this can be an arduous process with many potential roadblocks. For my projects, I’ve found it particularly helpful to be embedded in the health system (or to have partners who are) and to have the project goals aligned closely with the health system’s goals.
Additionally, knowing where the data are can make a huge difference. I’ve found that occasionally, you have to guide data analysts to the data you need. The best way to do this is to familiarize yourself with your health system’s EMR and data warehouses.
Data Preparation
Having obtained data, model developers may realize that healthcare data, like healthcare itself, is complicated. Processing and transforming data for AI model development requires a unique mix of clinical and technical expertise. Preparing this data for AI involves:
- Cleaning it.
- Dealing with missing values.
- Transforming it into a format that algorithms can work with.
This step is usually labor-intensive; 90% of the engineering time will be dedicated to data preparation. Tools can help automate data preparation. I made a tool called TemporalTransformer that can help you quickly convert longitudinal EMR or claims data into a sequential token format ready for processing with neural networks or foundation models. I discuss it in the supplement of my paper on predicting return to work.
Model Training
Training the model may be the most exciting step for the technical folks. But it’s often one of the shortest parts of the project (in terms of wall time, not CPU/GPU time). In this step, we select algorithms, tune parameters, and iteratively improve the model based on its performance. This step is a mix of science, art, and a bit of luck. The goal is to develop a model that’s both performant and generalizable. There are many resources dedicated to model training and lots of nitty gritty to do into, I’ll save that all for another blog post.
Model Validation
After being developed, models must be validated to assess whether they benefit patients, physicians, or healthcare systems. Validation means testing the model on new, unseen data to ensure it performs well in settings representative of intended real-world usage. Ultimately, we must ensure the model doesn’t just memorize the data it’s seen but can also make good predictions when used in practice.
This step often involves internal and external validation to ensure robustness. There are varying definitions for internal and external validation, but the distinction I like to use is based on the system generating the underlying data. If the data comes from the same system (e.g., the same hospital, just a different time period), it is internal validation data. A well-conducted external validation is a great way to assess whether a model will work in a new environment. However, external validation may be challenging due to data-sharing restrictions. Despite this challenge, it is often a great place to engage with healthcare AI systems, especially for physicians. Here are some examples of external validation studies that I’ve worked on:
- Assessing the Epic sepsis model,
- External validation of the Epic deterioration index on inpatients with COVID-19,
- Evaluation and development of radical prostatectomy outcome prediction models.
Wrapping Up
We’ve taken a closer look at the development phase of healthcare AI. Each step is requires a blend of clinical insight and data science expertise. While we’ve covered a lot of ground here, each development step could merit a more detailed post; please let me know if that’s something you would be interested in reading. Also, if you have developed healthcare AI models, I’d love to know what challenges you have faced.
Once you’ve developed a model, the next step is integration into healthcare workflows. Learn about that process in the post on Healthcare AI Implementation.
Thank you for joining me on this exploration of healthcare AI development.
Some of this content was adapted from the introductory chapter of my doctoral thesis, Machine Learning for Healthcare: Model Development and Implementation in Longitudinal Settings.
Cheers,
Erkin
Go ÖN Home
-
“If you wish to make an apple pie from scratch, you must first invent the universe.” - Carl Sagan ↩

