
Healthcare AI Infrastructure
For a general overview of the healthcare AI lifecycle, check out the introductory post.
This post started as a brief overview of healthcare AI infrastructure and then grew into an unwieldy saga incorporating my perspectives on building and implementing these tools. As such, I split the post into a couple of parts.
In this post we will review the existing HIT landscape and provide a general set of approaches for development and implementation. This’ll be followed by detailed posts on development and implementation. These posts provide more technical details and discuss a couple of projects I’ve shepherded through the AI lifecycle.
Additionally, this series will focus on AI models that interact with electronic medical records (EMR) and related enterprise IT systems used by health systems. This focus is partly due to my expertise—I worked for an EMR vendor and have built and deployed several models in this setting. However, it is also a natural interaction point. We connect AI models with EMRs because EMRs are the software systems most closely tied to care delivery. Given this framing, we will now lay out the significant components.
Basic Healthcare IT Infrastructure
Let’s start by grounding our conversation on the most fundamental healthcare information technology (HIT) infrastructure component: electronic medical records systems (EMRs). We will focus on EMRs because they are often the source and destination of information processed by healthcare AI systems. A solid understanding of the subcomponents of the EMR is necessary for creating healthcare AI infrastructure.
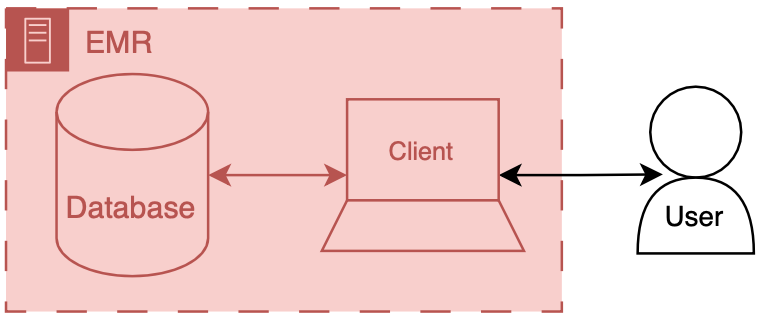
You can think of an EMR system as having two main components: a database and a client. The database’s primary job is to store the EMR’s underlying data—patient names, demographics, vitals, labs, notes, and any other necessary clinical data. The client’s job is to present the information in a way that the user can understand.
There’s a lot of additional code, configuration, and data that we won’t discuss directly, but these supporting artifacts help to round out the functionality of the database and the client. There are special names for these amalgamations: front end and back end. The term front end refers to the client and its supporting code, configuration, and data handling mechanisms. Back end refers to the database and all of its supporting configuration and communication code, along with any other code that drives the logic and behavior of the EMR.
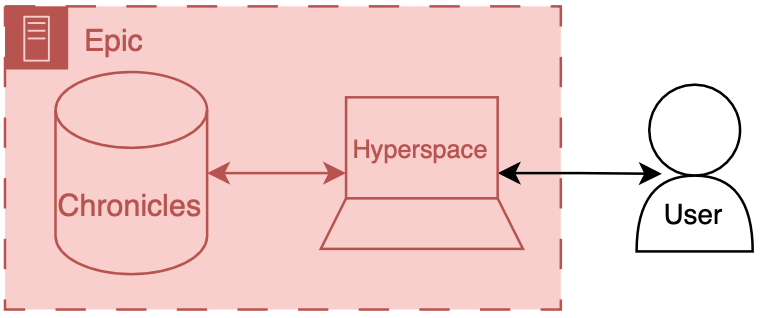
To make things more concrete, we will briefly discuss the Epic-specific names for these components.
Back end: Chronicles
Epic has a large back end written in a programming language called MUMPS (it is also known as M or Caché, which is a popular implementation of the language). MUMPS is an interesting language for various reasons (integrated key-value database, compact syntax, permissive scoping). So I might write about it more in the future, but Aaron Cornelius has some nice posts on the vagaries of MUMPS code. The database management system that holds all of the operational real-time clinical data is called Chronicles, it is implemented using MUMPS for both the data storage and code controlling database logic, schema, indexing, etc.
Front end: Hyperspace
There are several distinct front ends for Epic; however, one is by far the most important: Hyperspace. Hyperspace is the big daddy interface found on all the computers in the clinic and the hospital. It started life as a Visual Basic application (I once heard a rumor that it was the largest Visual Basic application ever made); however, it is now primarily a .NET application. If you’re a doctor, you may also interact with Epic’s other client software, such as Haiku (a mobile phone client) and Canto (an iPad client). There’s also MyChart, a front end that enables patients to review their records and communicate with their healthcare team.
Hyperspace is the primary place where clinical work is done. It is where notes are written, orders are placed, and lab values are reviewed. These workflows are the primary places where additional contextual information is helpful or where you want to serve a best practice alert. Thus, Hyperspace is the most likely end-target for most of our healthcare AI efforts.
There are a couple of ways to get information into Hyperspace. The first is to insert data into the underlying database, Chronicles, and integrate the information into the EMR’s underlying mechanics. The second is to have Hyperspace display a view of the information but serve it from a different source (like your own web server). This is usually done through a iframe.1 These options are not limited to Epic EMRs; you should be able to take either approach with any modern EMR system.
Now that we have discussed the basic healthcare IT landscape, we can start to discuss the specifics of making AI tools for healthcare.
AI Development Infrastructure
Now, we can start to dig into the fun stuff - the actual building of healthcare AI models. To start building an AI model, you need two things: data and a development environment (a computer). Data often comes in the form of a report or extract from a database (usually the EMR’s database). These data are then used to train a model using a computing environment set up for this purpose. These environments tend to be configured with special software and hardware, which allow model developers to write code to develop and evaluate a model.
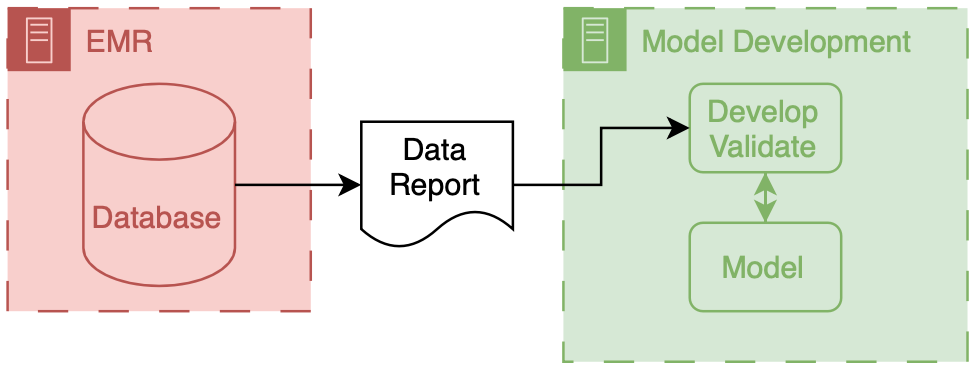
The above figure depicts the generic data flow for model development. Generally, the data will flow linearly from a source clinical system to our model development environment.
AI Implementation Infrastructure
Now we focus on connecting models into care processes, implementation. As discussed in the previous post, implementation goes beyond the technology, however, the primary focus of this section will be on the implementation step of technical integration, the nuts-and-bolts of connecting AI models to existing HIT systems.
There are two primary ways to integrate a model into existing HIT systems, and the relationship to the EMR delineates them as internal and external.
Internal integration of models means that developers rely exclusively on the tooling provided by the EMR vendor to host the model along with all of the logic that controls the running of the model and filing of its results.
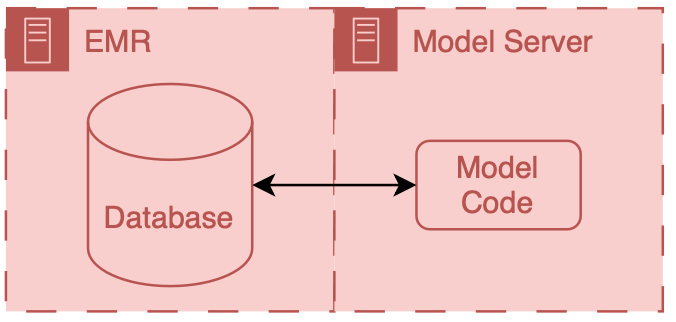
External integration of models means that developers own some parts of the hosting, running, or filing (usually the hosting piece).
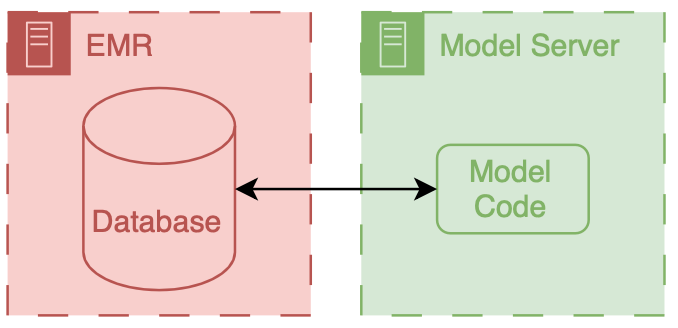
In both scenarios, data flows from the EMR database to the model; however, the path these data take can be drastically different, and significant thought should be put into the security of the data and the match between the infrastructure and the model’s capabilities.
It is important to note that these approaches delegate the display of model results to the EMR system. They do this by passing model results to the EMR and using EMR tools to display the results to users.
A Note on Color Coding
Throughout this series, I have employed a consistent color coding scheme to identify the owners of different HIT components.
Everything made and maintained by the EMR vendor (or their proxies) is red  .
Components owned by AI model developers are colored green
.
Components owned by AI model developers are colored green  .
Components that the health system or research enterprise may own are blue
.
Components that the health system or research enterprise may own are blue  .
Elements that don’t fit directly in one of these buckets are outlined in black
.
Elements that don’t fit directly in one of these buckets are outlined in black  .
.
What’s next?
Because it’s a shiny new toy, healthcare AI can sometimes seem like it should be in a class of its own compared to existing technologies. This is absolutely not the case; good healthcare AI is good HIT. I think there is no real distinction between HIT and healthcare AI because they interact with the same data and users.
A comprehensive understanding of EMRs and associated clinical care systems is paramount in developing and implementing healthcare AI models. This post is followed by detailed posts on AI development infrastructure and implementation infrastructure.
Cheers,
Erkin
Go ÖN Home
-
This can be complicated because you need to maintain your own application server and also deal with passing authentication between the EMR session and your application. ↩


